一年一度的“双十一”又要来了,很多人已经开始摩拳擦掌,毕竟几天之后手还在不在就不好说了。
各种社交软件也是跟着遭殃,整天就是“来帮我一起盖楼”,各种字体绕过屏蔽,什么奇葩的脑洞也出来了:  不过也感谢这些电商平台,让多年未联系的好友、加过但没有对话的陌生人都找到了打破尴尬的话题。(让场面更加尴尬)
不过也感谢这些电商平台,让多年未联系的好友、加过但没有对话的陌生人都找到了打破尴尬的话题。(让场面更加尴尬)
月薪上万的白领们为了2块5毛钱的优惠券起早贪黑,也是堪称人类迷惑行为大赏了……
问题是,你以为自己真的赚到了?
商品“明降暗升”的传言早有耳闻:很多商品在双十一之前早早地把价格调高,加上优惠之后也不过就是跟以前的原价相当。让不知情的消费者在心理上感觉占了便宜。
这个传言是不是真的,很好判断,只要定期去访问商品页面,记录价格就可以。不过一般人也没闲工夫这么去做。于是,我们用 Python 做了一个可以定时监控商品的小工具,可以帮你监控想要关注的商品。
工具完成之后,我们随机挑选了几个商品作为测试,结果就有一个中招了……(真的是随便选的):  这款保暖背心产品,之前标价 39.9元,到11月之后却突然调价为 49.9元,并标注上了“双11狂欢价”,也就是原价……
这款保暖背心产品,之前标价 39.9元,到11月之后却突然调价为 49.9元,并标注上了“双11狂欢价”,也就是原价…… 

商品价格监控
实现功能
-
输入天猫、苏宁、京东、拼多多(网页页面 http://yangkeduo.com/)任一商品链接,不是口令。请复制选择好商品配置的页面链接,即返回相应商品价格,并保存到文件。商品页面若有团购与单独购买两个价格,返回团购价格。
-
使用 Windows 任务计划或 Linux 定时任务,定时执行程序。获取不同时段的商品价格信息。
-
单独运行画图程序,可根据定时任务获取的数据,生成商品价格时间变化折线图。
-
程序监测的两件商品截图如下,具体文件在 pic 文件夹下 bnbx.html、kyy.html,推荐本地查看。 
 简单的商品查看页面
简单的商品查看页面 https://htmlpreview.github.io/?https://raw.githubusercontent.com/spiderbeg/price_monitor/master/search/search.html 。输入查询商品关键词,选择商城,即可查看相应商城商品列表。默认为苏宁。效果图如下。注意:点击后请等待一段时间即可,请勿频繁刷新。 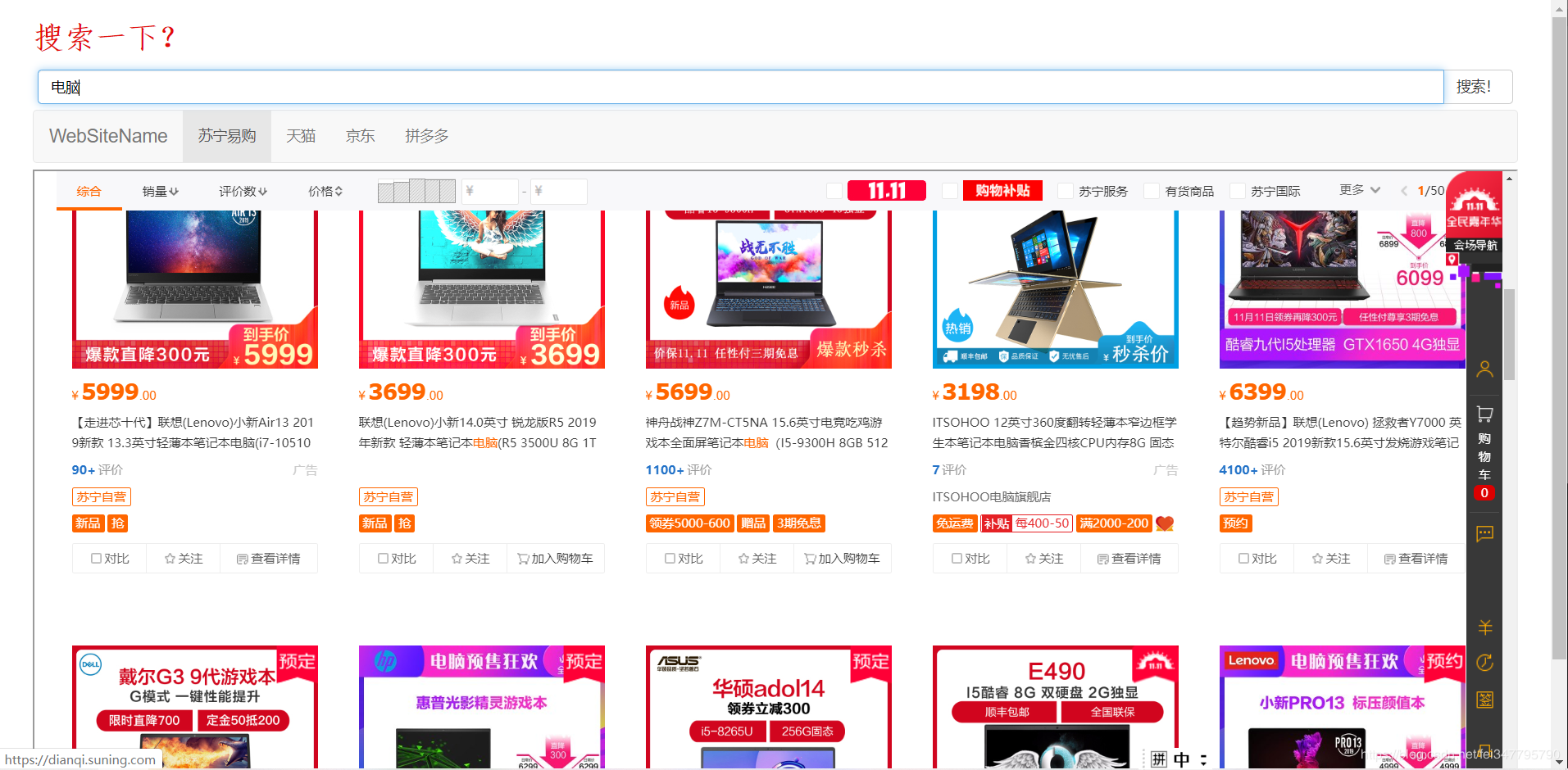
运行环境
-
python3.7
-
Windows
-
jupyter notebook
运行依赖包
-
requests
-
pyecharts
-
beautifulsoup4
项目思路
部分问题回答
项目的大致思路流程:
因为在未登录状态天猫的详细商品页的信息是虚假的,同时从移动端网页入手,可以降低调试难度。
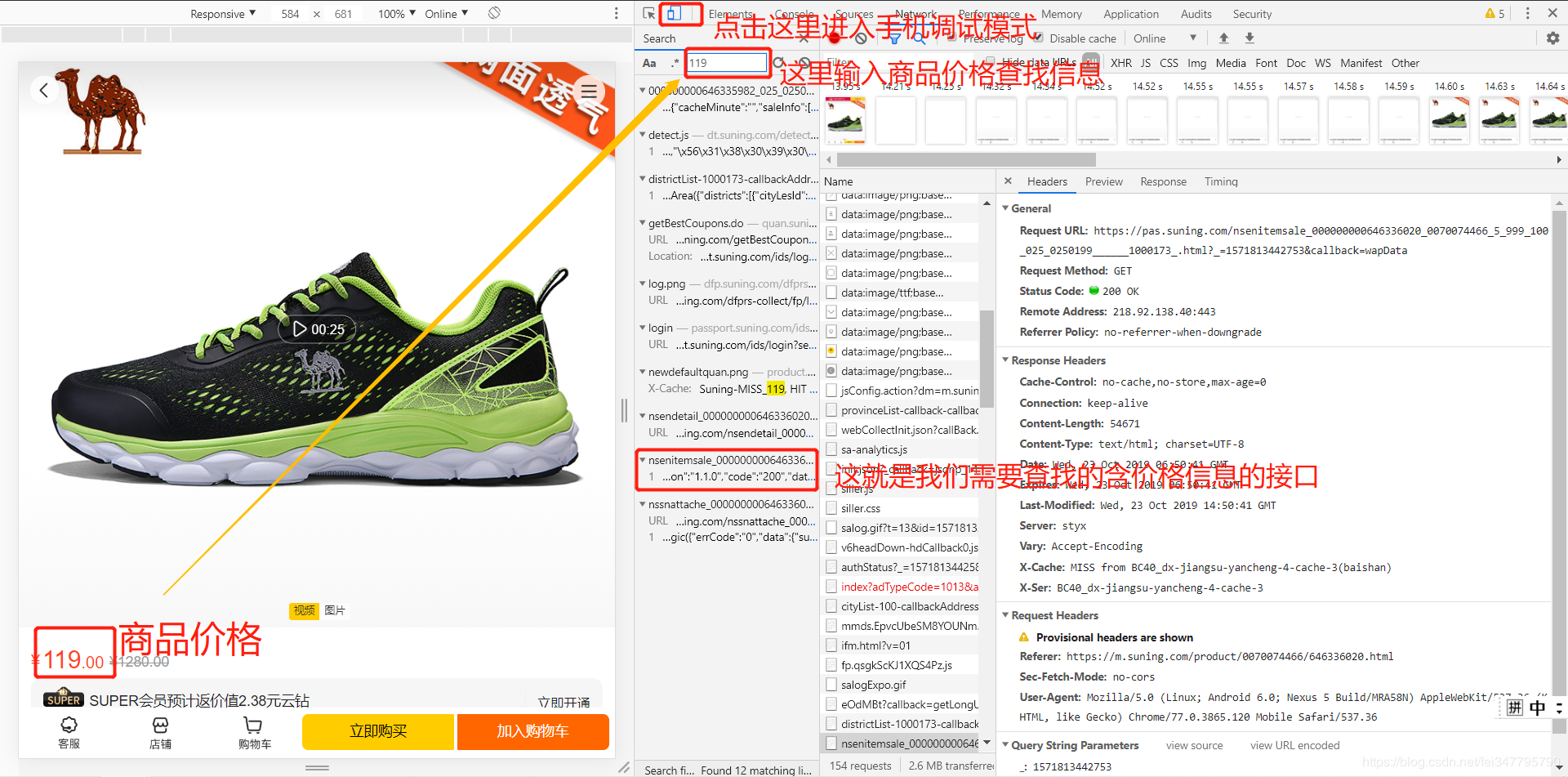
谷歌浏览器如何开启手机调试模式?
F12 进入开发者模式,然后鼠标点击一下,具体见下图,包括后文的查找价格接口信息。
实现代码
test.py
- import timing
"""
1 调用 timing.py 中的 go 方法测试链接的可用性
2 调用 timing.py 中的 go, get_url() 方法测试 goods.csv 文件中链接的可用性
python学习交流群:821460695更多学习资料可以加群获取
"""
?
timing.py
