我们经常需要汇总数据而不用把它们实际检索出来,为此MySQL提供了专门的函数。使用这些函数,MySQL查询可用于检索数据,以便分析和报表生成。
这种类型的检索例子有以下几种:
- 确定表中行数(或者满足某个条件或包含某个特定值的行数)。
- 获得表中行组的和。
- 找出表列(或所有行或某些特定的行)的最大值、最小值和平均值
如:
- AVG() 返回某列的平均值
- COUNT() 返回某列的行数
- MAX() 返回某列的最大值
- MIN() 返回某列的最小值
- SUM() 返回某列值之和
-
-
举个例子:
- select AVG(prod_price) as avg_price
- from products
-

再比如说:

这里有些函数里面可以设置distinct,比如avg,如果设置了的话,那么会有一个这样的现象。就是只统计了不同值之间的平均值,具体看业务需求。
下面介绍分组数据:
返回每个供应商提供的产品数目:
- select COUNT(*) as num_prods,vend_id
- from products
- GROUP BY vend_id
-

使用group by 需要注意的地方:
GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制- 如果在
GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)
GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。- 除聚集计算语句外,
SELECT语句中的每个列都必须在GROUP BY子句中给出。
- 如果分组列中具有NULL值,则
NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
使用ROLLUP 使用WITH ROLLUP关键字,可以得到每个分组以
及每个分组汇总级别(针对每个分组)的值,
如下所示:
- select COUNT(*) as num_prods,vend_id
- from products
- GROUP BY vend_id with ROLLUP
-
除了能用GROUP BY分组数据外,MySQL还允许过滤分组,规定包括哪些分组,排除哪些分组。例如,可能想要列出至少有两个订单的所有顾客。为得出这种数据,必须基于完整的分组而不是个别的行进行过滤。
HAVING和WHERE的差别 这里有另一种理解方法,WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
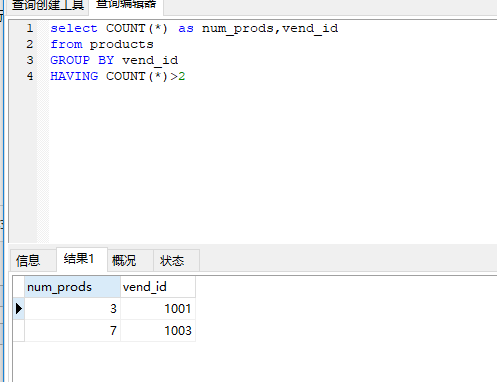
- select COUNT(*) as num_prods,vend_id
- from products
- GROUP BY vend_id
- HAVING COUNT(*)>2
-
那么,有没有在一条语句中同时使用WHERE和HAVING子句的需要呢?事实上,确实有。假如想进一步过滤上面的语句,使它返回过去12个月内具有两个以上订单的顾客。为达到这一点,可增加一条WHERE子句,过滤出过去12个月内下过的订单。然后再增加HAVING子句过滤出具有两个
以上订单的分组。
- select COUNT(*) as num_prods,vend_id
- from products
- where prod_price>=10
- GROUP BY vend_id
-

下面介绍一下order by:
虽然GROUP BY和ORDER BY经常完成相同的工作,但它们是非常不同的。
这里为什么说group by 与 order by完成相同的工作呢?这是因为前面我们发现没,就是其实看起来好像是经过了vend_id的排序的。
我们经常发现用GROUP BY分组的数据确实是以分组顺序输出的。但情况并不总是这样,它并不是SQL规范所要求的。此外,用户也可能会要求以不同于分组的顺序排序。仅因为你以某种方式分组数据(获得特定的分组聚集值),并不表示你需要以相同的方式排序输出。
应该提供明确的ORDER BY子句,即使其效果等同于GROUP BY子句也是如此
不要忘记ORDER BY 一般在使用GROUP BY子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY排序数据。
例如:
- select COUNT(*) as num_prods,vend_id
- from products
- where prod_price>=10
- GROUP BY vend_id
- ORDER BY num_prods
-
-
select 语句顺序:
- SELECT 要返回的列或表达式 是
- FROM 从中检索数据的表 仅在从表选择数据时使用
- WHERE 行级过滤 否
- GROUP BY 分组说明 仅在按组计算聚集时使用
- HAVING 组级过滤 否
- ORDER BY 输出排序顺序 否
- LIMIT 要检索的行数 否
到此这篇关于mysql 数据汇总与分组的文章就介绍到这了,更多相关mysql 分组内容请搜索w3xue以前的文章或继续浏览下面的相关文章希望大家以后多多支持w3xue!
