''' 爬取豆瓣电影排行榜 设计思路: 1、先获取电影类型的名字以及特有的编号 2、将编号向ajax发送get请求获取想要的数据 3、将数据存放进excel表格中'''
环境部署:
软件安装:
- Python 3.7.6
- PyCharm 2020.2.2 x64 位
模块安装(打开cmd或powershell进行下面的命令安装【前提需要有python】):
- 安装requests模块、lxml模块(发送请求,xpath获取数据)
pip install requests #(主要用来发送请求,获取响应)pip install lxml #(主要引用里面的etree里面的xpath方法)
- 安装xpathhelper插件(可以在网页中复制相应的节点xpath路径并查看)
1、下载地址:https://pan.baidu.com/s/1UM94dcwgus4SgECuoJ-Jcg 密码:337b2、window平台下: · 把文件的后缀名crx改为rar,然后解压到同名文件夹中 · 打开谷歌的扩展程序 ——> 进入到管理管理扩展程序中 · 打开开发者模式,通过加载已解压的扩展程序,将插件导入3、ios平台下: · 直接将crx文件拖进扩展程序中
pip install xlwt
项目中需要引入的模块:
import requestsfrom lxml import etreeimport xlwtimport time
使用流程:
- 在列表中填写所需要获取的电影类型名
- 输入开始时获取的start以及获取多少数据的limit
- 填写所要输出的excel表格的名字(代码中默认douban.xls)
- 程序运行结束后打开excel验证数据是否获取
- 观察自己所需的数据
完整代码:
# encoding=utf8# 编程者 :Alvin''' 爬取豆瓣电影排行榜 设计思路: 1、先获取电影类型的名字以及特有的编号 2、将编号向ajax发送get请求获取想要的数据 3、将数据存放进excel表格中'''import requestsfrom lxml import etreeimport xlwtimport timeclass DouBan(): # 初始化数据,获取最外层的数据 def __init__(self, name_list): self.headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.3", "Connection": "close", "Referer": "https://movie.douban.com/" } # 获取最外层的数据,并拿到url中的type中的name 和 类型 self.url = 'https://movie.douban.com/chart' self.dydata_list = [] # 电影的类型名 self.name_list = name_list # 实例化excel表格对象 self.wb = xlwt.Workbook() # 通过电影的类型名字获取对应的类型号 def get_data_typenum(self, name): for data in self.dydata_list: if data['name'] == name: typenum =data['dytype'] else: continue return typenum # 获取数据 def get_data_p1(self): response = requests.get(self.url , headers = self.headers) # 判断长度是否足够大 # print(len(response.content.decode())) return response.content.decode() # 获取下一层的页面数据 def get_data_p2(self, typenum, num, limit): url = 'https://movie.douban.com/j/chart/top_list' params = { 'type': typenum, 'interval_id': '100:90', 'action':'', 'start': num*20, 'limit': limit } response = requests.get(url,params=params,headers=self.headers) # print(response.json()) return response.json() # 处理数据 def data_parse_p1(self, data): html = etree.HTML(data) data_list = html.xpath('//div[@class="types"]/span/a/@href') # 用于收集类型名字 name_list = [] dytype_list = [] # 用于收集类型号 for data in data_list: name = data.split('?')[-1].split('&')[0].split('=')[-1] dytype = data.split('?')[-1].split('&')[1].split('=')[-1] name_list.append(name) dytype_list.append(dytype) for (name,dytype) in zip(name_list,dytype_list): dydict = {} dydict['name'] = name dydict['dytype'] = dytype self.dydata_list.append(dydict) # print(self.dydata_list) return self.dydata_list def data_parse_p2(self, data_list,name): print(len(data_list)) douban = self.wb.add_sheet(name) style = xlwt.XFStyle() # 初始化一个style对象,用来保存excel的样式 font = xlwt.Font() # 创建一个font对象,用来保存对字体进行的操作 font.name = '微软雅黑' # 字体设置为'微软雅黑' font.bold = True # 字体加粗 al = xlwt.Alignment() # 创建一个对齐对啊想,用来改变文本内容的字体 style.font = font # 将字体信息保存到style对象中 style.alignment = al # 水平对齐方式、水平居中 al.horz = 0x02 # 垂直对齐方式、垂直居中 al.vert = 0x01 # 电影的标题 douban.col(0).width = 256 * 25 # 电影演员的名字 douban.col(1).width = 256 * 50 # 电影上映的年份 douban.col(2).width = 256 * 15 # 电影上映的国家 douban.col(3).width = 256 * 15 # 电影的标签 douban.col(4).width = 256 * 20 # 电影的评分 douban.col(5).width = 256 * 8 # 豆瓣中该电影的页面链接 douban.col(6).width = 256 * 40 douban.write(0, 0, '电影标题', style) douban.write(0, 1, '电影演员名字', style) douban.write(0, 2, '电影上映年份', style) douban.write(0, 3, '电影上映国家', style) douban.write(0, 4, '电影标签', style) douban.write(0, 5, '电影评分', style) douban.write(0, 6, '豆瓣中该电影的页面链接', style) row = 1 for data in data_list: # 电影的标题 title = data['title'] # 电影演员的名字 actors = data['actors'] # 电影上映的年份 release_date = data['release_date'] # 电影上映的国家 regions = data['regions'][0] # 电影的标签 types = data['types'] # 电影评分 score = data['score'] # 豆瓣查看的链接 link = data['url'] douban.write(row, 0, title) douban.write(row, 1, actors) douban.write(row, 2, release_date) douban.write(row, 3, regions) douban.write(row, 4, types) douban.write(row, 5, score) douban.write(row, 6, link) row += 1 self.wb.save('douban.xls') # 运行程序 def run(self, num, limit): # 获取第一层中的所需要的类型名字和数字 self.data_parse_p1(self.get_data_p1()) for name in self.name_list: typenum = self.get_data_typenum(name) # 向指定的分类进行数据的访问 data_list = self.get_data_p2(typenum,num,limit) # 对获取的数据进行解析保存 self.data_parse_p2(data_list,name)if __name__ == '__main__': # 需要查看的类型 douban = DouBan(['喜剧','悬疑','惊悚']) # 需要查看的开始值start,以及需要查看的数量limit douban.run(0,100) time.sleep(2)
效果图
- pycharm 运行台
- excel表格显示
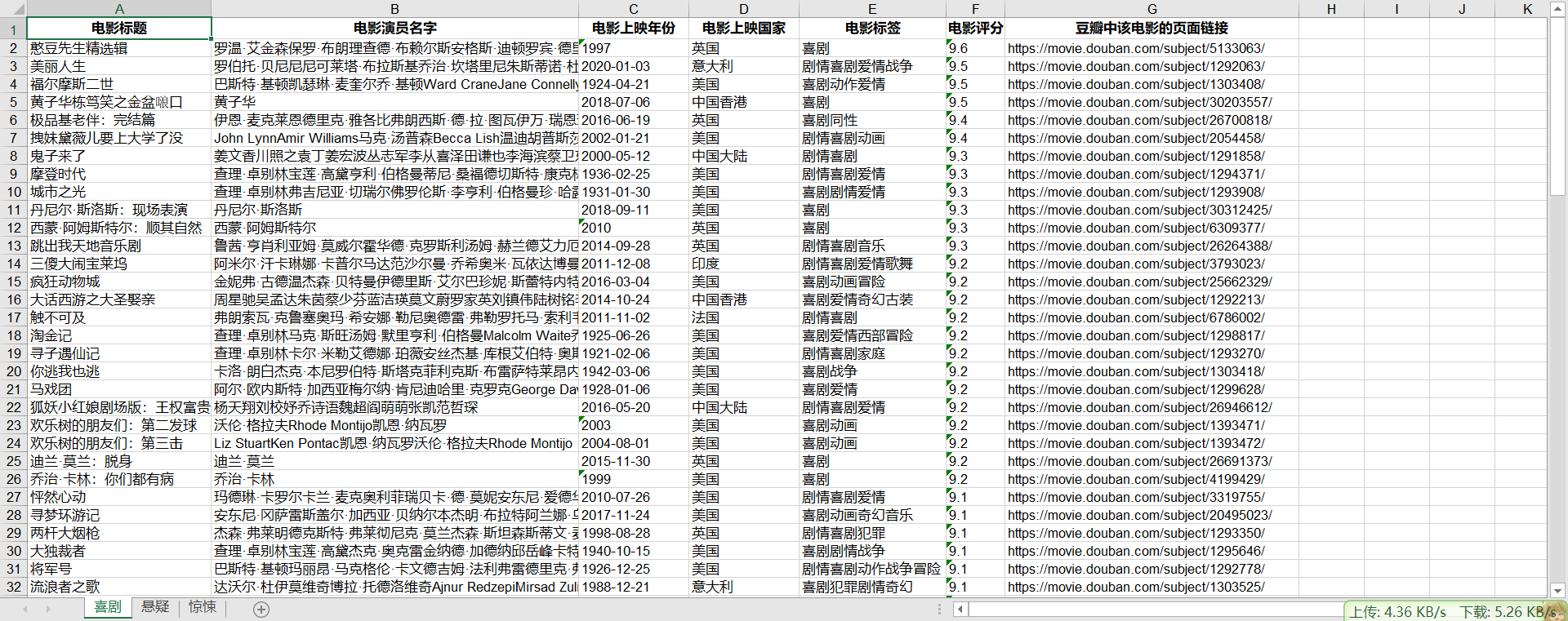
本案例笔者的想法是打算先获取到每一个电影类型的前100个数据,然后在excel表格中进行评分的筛选,最后观察现阶段某个电影类型中哪些电影在豆瓣电影中评分较高的
