关于函数的说明
字符函数
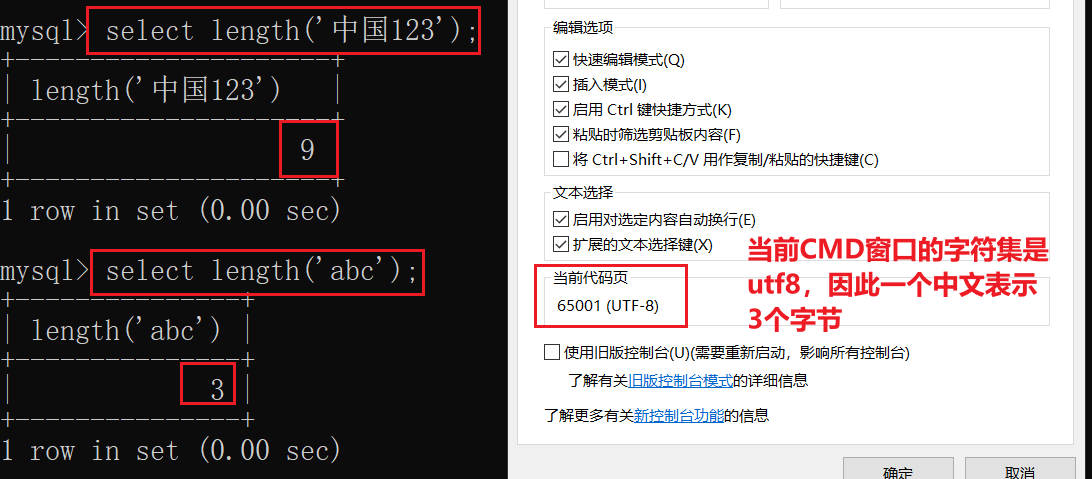
length(str)
- 获取参数值的字节个数
- 对于
utf8字符集来说,一个英文占1个字节;一个中文占3个字节
- 对于
gbk字符集来说,一个英文占1个字节;一个中文占2个字节
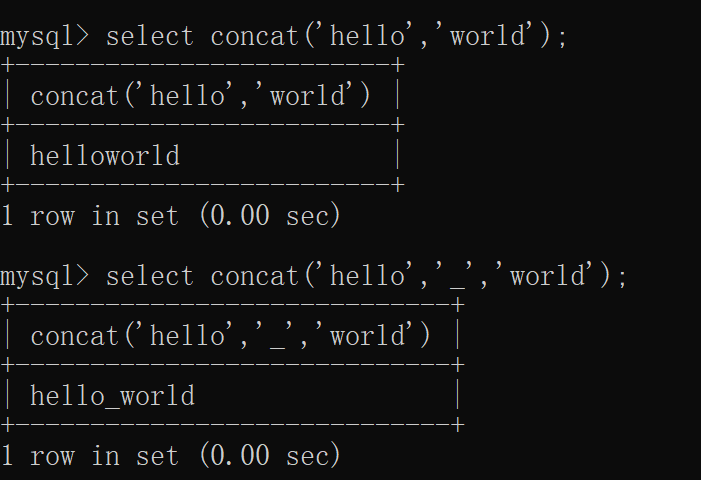
concat(str1,str2,...)
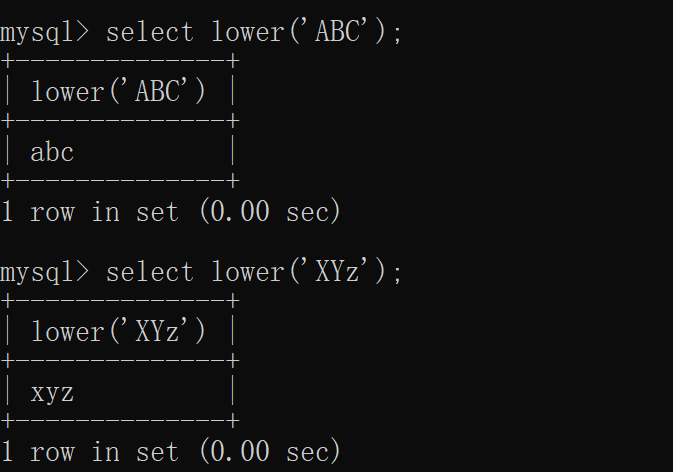
upper(str)

lower(str)
substr(str,start,len)
- 从start3位置开始截取字符串,len表示要截取的长度
- 没有指定len长度:表示从start开始起,截取到字符串末尾。
- 指定了len长度:表示从start开始起,截取len个长度。

instr(str,要查找的子串)
- 返回子串第一次出现的索引,如果找不到,返回0
- 当查找的子串存在于字符串中:返回该子串在字符串中【第一次】出现的索引。
- 当查找的子串不在字符串中:返回0。

trim(str)
- 去掉字符串前后的空格
- 该函数只能去掉字符串前后的空格,不能去掉字符串中间的空格。

lpad(str,len,填充字符)

rpad(str,len,填充字符)

replace(str,子串,另一个字符串)

数学函数
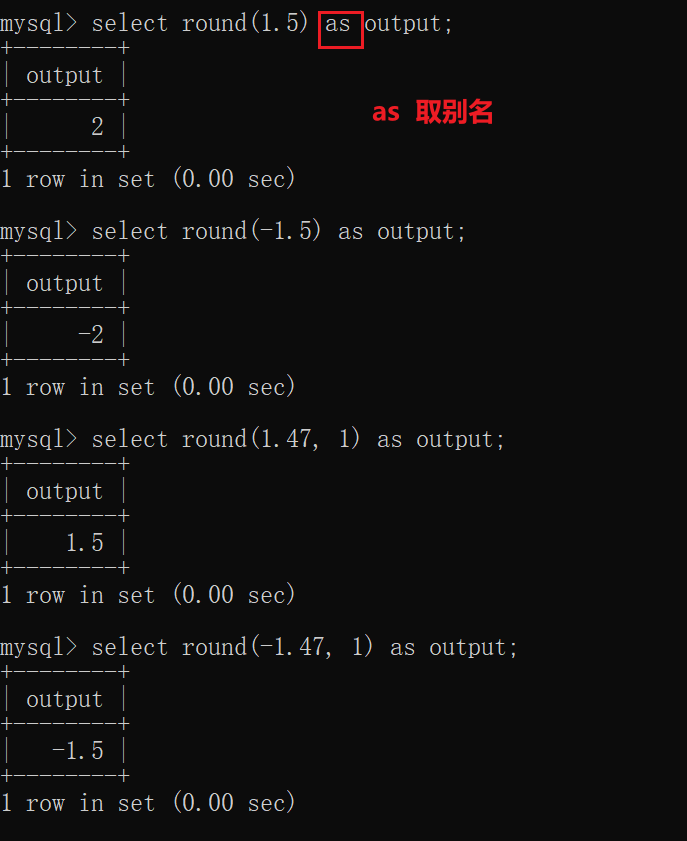
round(x,[保留的位数])
- 四舍五入
- 当对
正数进行四舍五入:按照正常的计算方式,四舍五入即可。
- 当对
负数进行四舍五入:先把符号丢到一边,对去掉负号后的正数进行四舍五入,完成以后,再把这个负号,补上即可。
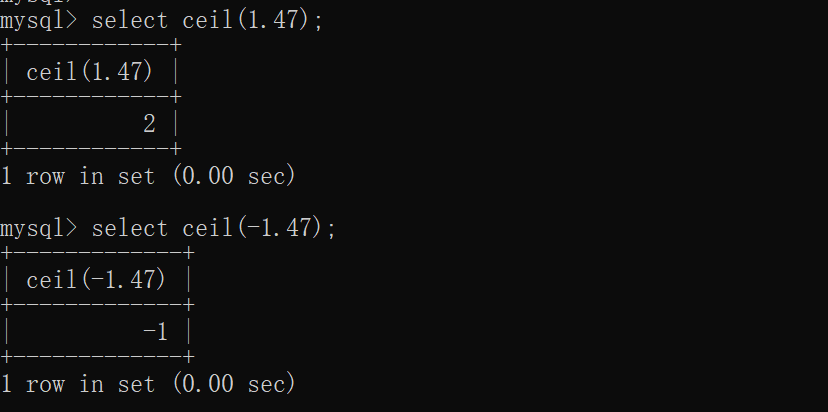
ceil(x)
- 向上取整,返回>=该参数的最小整数,又称为天花板函数
- 天花板函数:在excel,python中均存在这个函数。你就想象一下你家的天花板,把这个数字丢到天花板上,求的是大于等于这个数字的最小整数。
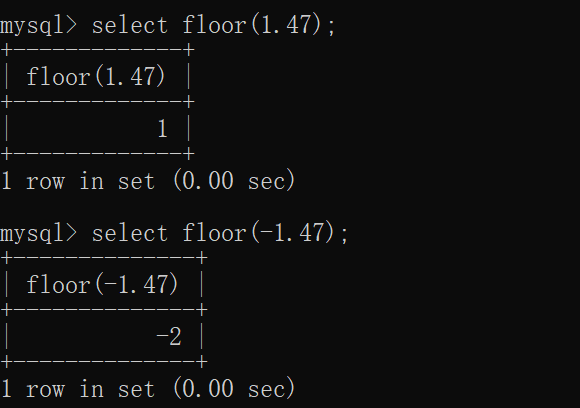
floor(x)
- 向下取整,返回<=该参数的最大整数。又称为地板函数
- 地板函数:在excel,python中均存在这个函数。你就想象一下你家的地板,把这个数字丢到地板上,求的是小于等于这个数字的最大整数。
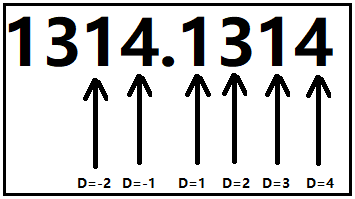
truncate(x,D)
- 截断:也是在excel,python中均存在,含义基本都是一致的。
理解如下:
"参考下面的示例图,体会如下文字"
-
D是正数,操作的是小数点右侧的小数部分。
- D=1,直接从第1个位置处,砍掉后面的部分。
- D=2,直接从第2个位置处,砍掉后面的部分。
- ......
-
D是0,直接去掉小数部分。
-
D是负数,操作的是小数点左侧的整数部分。
- D=-1,直接从-1位置处,先砍掉后面的小数部分,并且"从当前位置起(包括当前位置),后面整数部分替换为0"。
- D=-2,直接从-2位置处,先砍掉后面的小数部分,并且"从当前位置起(包括当前位置),后面整数部分替换为0"。
- ……
示例图:
操作如下:

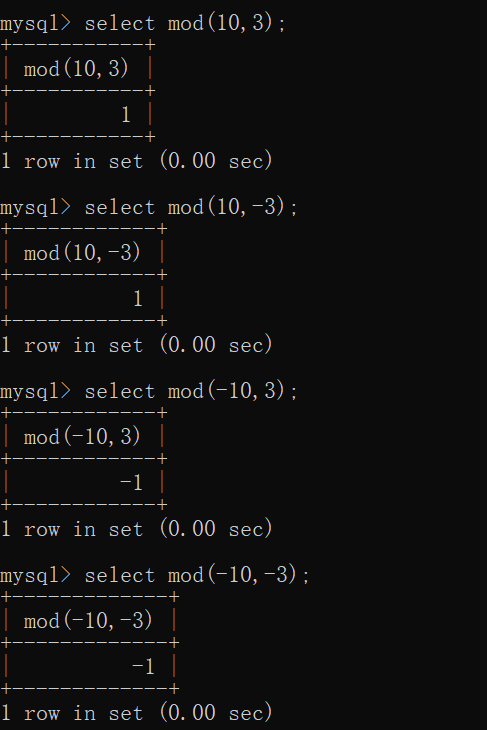
mod(被除数,除数)
- 取余
- 当被除数为正数,结果就是正数。
- 当被除数为负数,结果就是负数。
操作如下:
日期时间函数
日期的含义:指的是我们常说的年、月、日。时间的含义:指的是我们常说的时、分、秒。
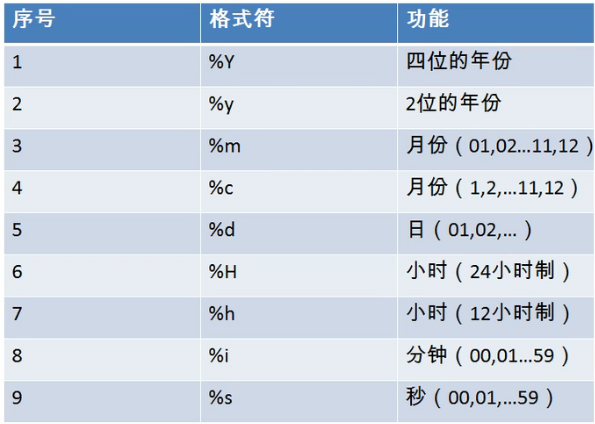
在讲述下面函数之前,我们先补充一个知识,不同时间格式符表示什么含义呢?
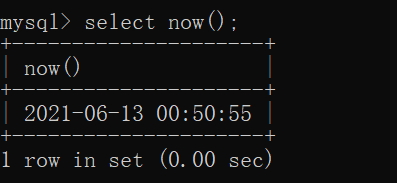
now()
操作如下:
curdate()
操作如下:

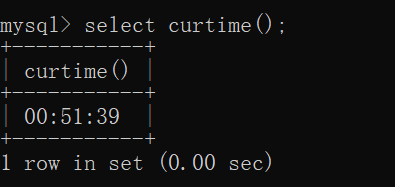
curtime()
操作如下:
获取日期和时间中年、月、日、时、分、秒;
- 获取年份:year(),例如:
select year(now()),返回系统当前的日期和时间中的年份。
- 获取月份:month(),例如:
select month(now()),返回系统当前的日期和时间中的月份。
- 获取日期:day(),例如:
select day(now()),返回系统当前的日期和时间中的日期。
- 获取小时:hour(),例如:
select hour(now()),返回系统当前的日期和时间中的小时。
- 获取分钟:minute(),例如:
select minute(now()),返回系统当前的日期和时间中的分钟。
- 获取秒数:second(),例如:
select second(now()),返回系统当前的日期和时间中的秒数。
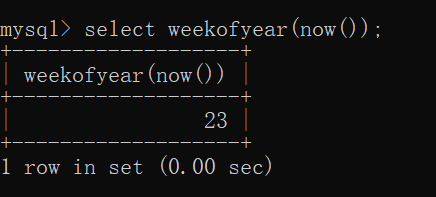
weekofyear()
操作如下:
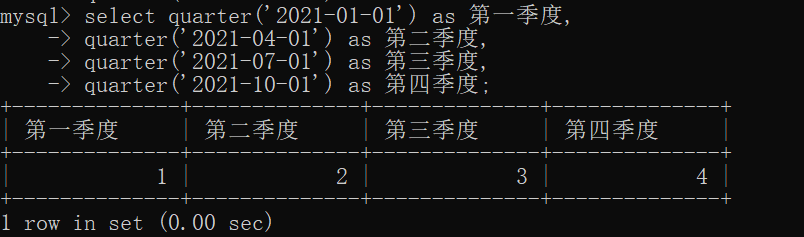
quarter()
操作如下:
str_to_date()
操作如下:

- 将日期转换成日期字符串
%Y-%m-%d返回的月份是01,02...这样的格式。%Y-%c-%d返回的月份是1,2...这样的格式。
操作如下:

date_add() + interval
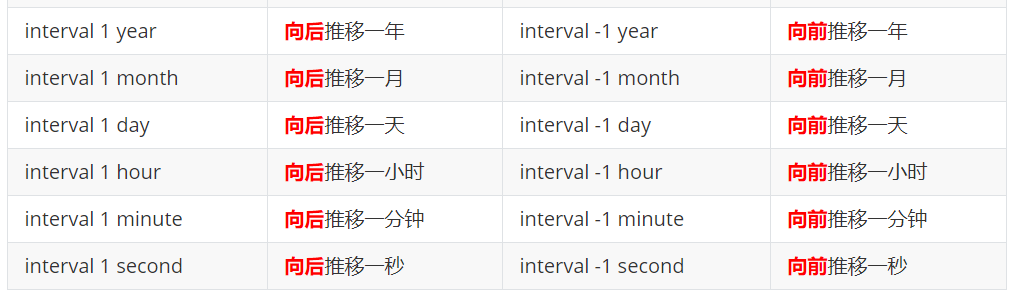
操作如下:

last_day()
操作如下:

datediff(end_date,start_date)
操作如下:

timestampdiff(unit,start_date,end_date)
操作如下:

流程控制函数
if函数
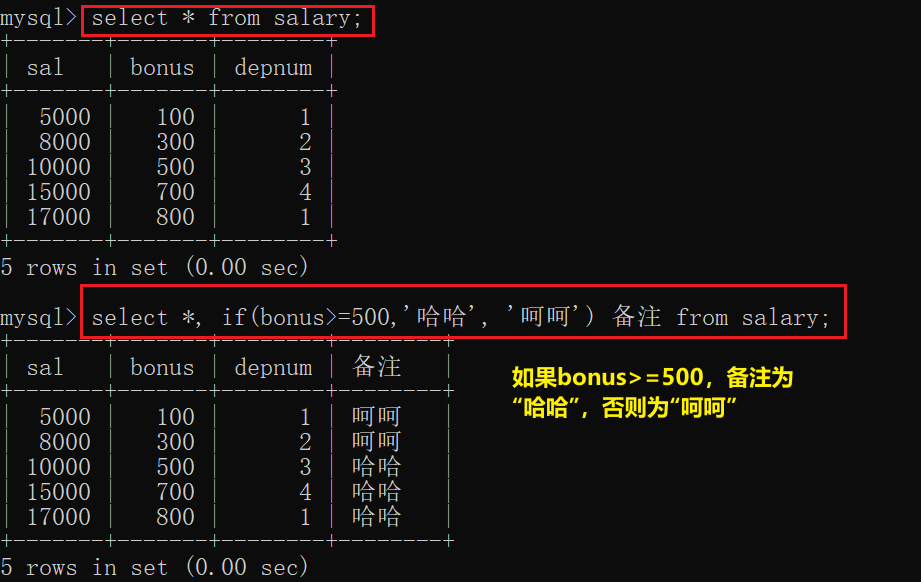
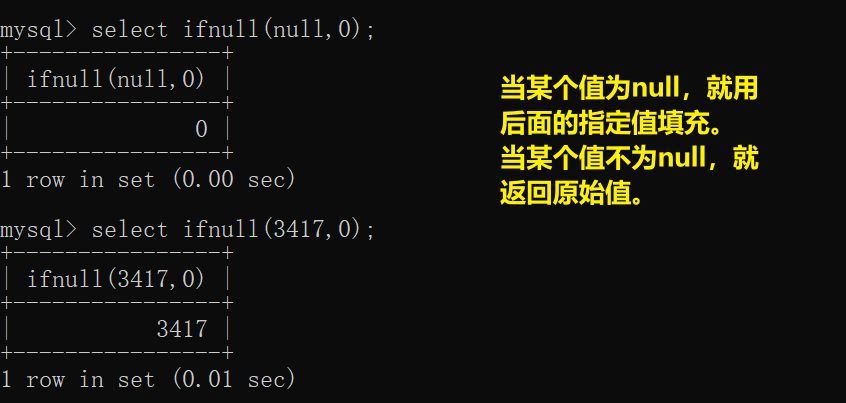
ifnull函数
case...when函数的三种用法
case ... when共有三种用法。
有如下数据:

① 等值判断:类似于java中switch case的效果
-- case ... when用作等值判断的语法格式case 要判断的字段或表达式when 常量1 then 要显示的值1或语句1when 常量2 then 要显示的值2或语句2...else 要显示的值n或语句end
操作如下:

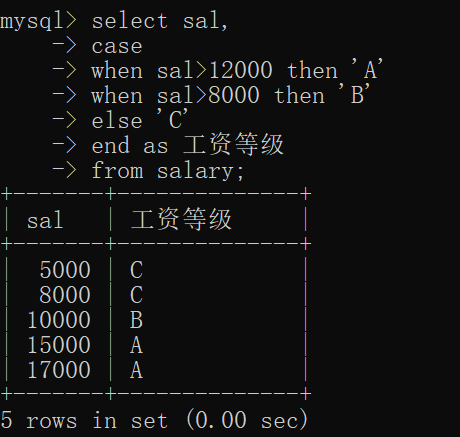
② 区间判断:类似于python中if-elif-else的效果
-- case ... when用作区间判断的语法格式case when 条件1 then 要显示的值1或语句1when 条件2 then 要显示的值2或语句2...else 要显示的值n或语句nend
操作如下:
③ case ... when和聚合函数联用
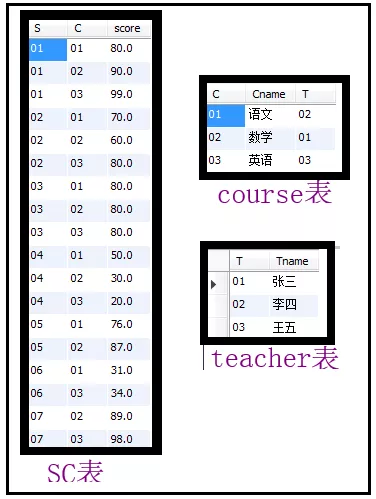
利用上述原始表,完成如下问题:
-- 18、查询各科成绩最高分、最低分和平均分,以如下形式显示:-- 课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率-- 及格为:>=60,中等为:70-80,优良为:80-90,优秀为:>=90
操作如下:
select sc.c,cname,max(score) 最高分,min(score) 最低分,avg(score) 平均分,sum(case when score>60 then 1 else 0 end)/count(*) 及格率,sum(case when score>=70 and score<80 then 1 else 0 end)/count(*) 中等率,sum(case when score>=80 and score<90 then 1 else 0 end)/count(*) 优良率,sum(case when score>=90 then 1 else 0 end)/count(*) 优秀率from sc left join course on sc.c = course.cgroup by sc.c;
结果如下:

测试数据:
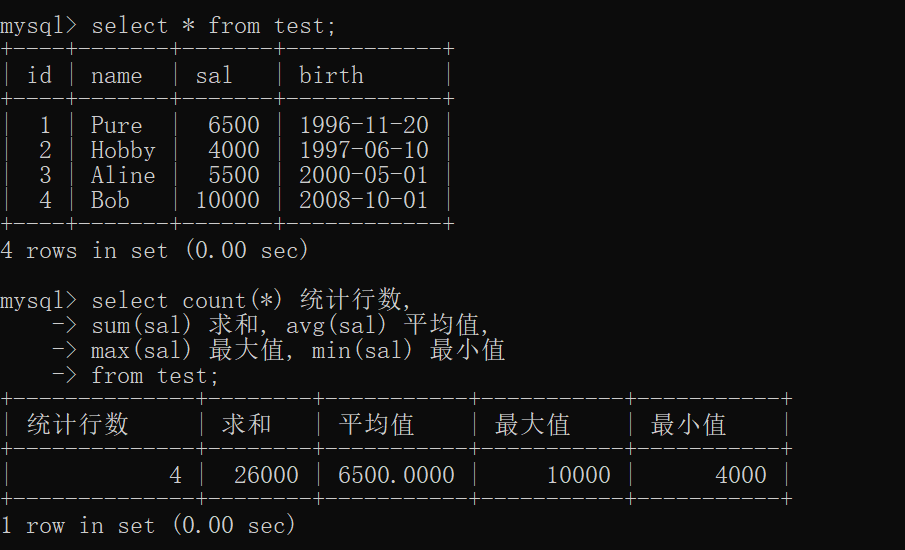
-- 建表语句create table test(id int primary key auto_increment,name varchar(20) not null,sal int,birth date)charset=utf8;-- 插入数据insert into test(name,sal,birth) values ("pure",6500,'1996.11.20'),("Hobby",4000,'1997.6.10'),("Aline",5500,'2000.5.1'),("Bob",10000,'2008.10.1');
聚合函数的简单使用
select * from test;select count(*) 统计行数,sum(sal) 求和, avg(sal) 平均值,max(sal) 最大值, min(sal) 最小值from test;
执行结果:
聚合函数中传入的参数,所支持的数据类型
mysql不是强类型的编程语言。也就是说,有些语句执行结果可能不报错,但是执行结果无实际意义,因此,我们也认为是不正确的。
sum()和avg()

结论如下:
- sum()函数和avg()函数对于字符串类型、日期/时间类型的计算都没有太大意义。因此,sum()函数和avg()函数,我们只用来对
小数类型和整型进行求和。
max()和min()

结论如下:
-
max()和min()中传入的是"整型/小数类型",计算的是数值的最大值和最小值。
-
max()和min()中传入的是"日期类型",max()计算的最大值是离我们最近的那个日期,min()计算的最小值是离我们最远的那个日期。
-
max()和min()中传入的是字符串类型,max()计算的最大值是按照英文字母顺序显示的,min()计算的最小值也是按照英文字母顺序显示的,意义不太大
count()
插入一条数据
insert into test(name) values('LiLei');
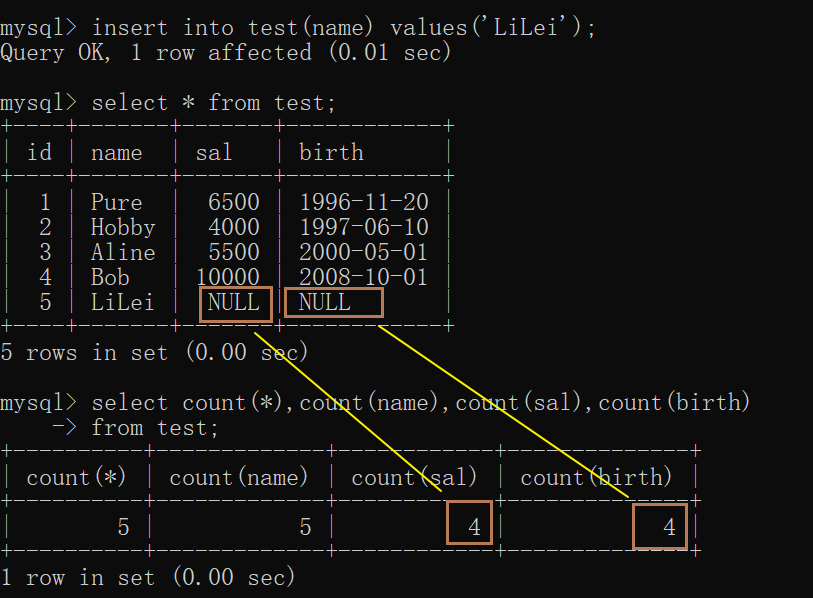
结论如下:
-
count()函数可以传入任何数据类型,表示对行计数。
-
但是下面的知识点需要特别注意的
-
首先看看count(sal),count(birth)这两句表示的是什么意思?这两句分别表示的是
对sal列字段、birth列字段的行数,进行统计。由于其中有一条记录是null值,因此使用count()
函数计数的时候,会忽略掉null行。
-
其次,对于count(\*)表示的是统计【整个表】有多少行,这个肯定是对原始数据的行数的正确
统计,只要整张表某一行有一个列字段的值不是null,count(\*)就会认为该行为1行。当然要是一
整行都是null值,你也没必要插入这条记录。
总结:当某个字段列中没有null值,则count(列字段)=count(*)。
当某个字段列中有null值,则count(列字段)<count(*)。 因此,假如你想统计的是整张表的行数,请用count(*)。
其实所有的分组函数都忽略null值的,但上面那个count()函数碰到null值要特别注意。

结论如下:
- 对于avg(sal)求平均值来说,(6500+4000+5500+10000)/4=6500。对于后面这个
sum()/count(*)求平均值来说,(6500+4000+5500+10000)/5=5200。
- 好好体会上述例子,有时候某人成绩虽然记录的是null,但是你仍然有5个人存在,所
以你要考虑一下怎么使用合适的函数,达到你想要的结果。
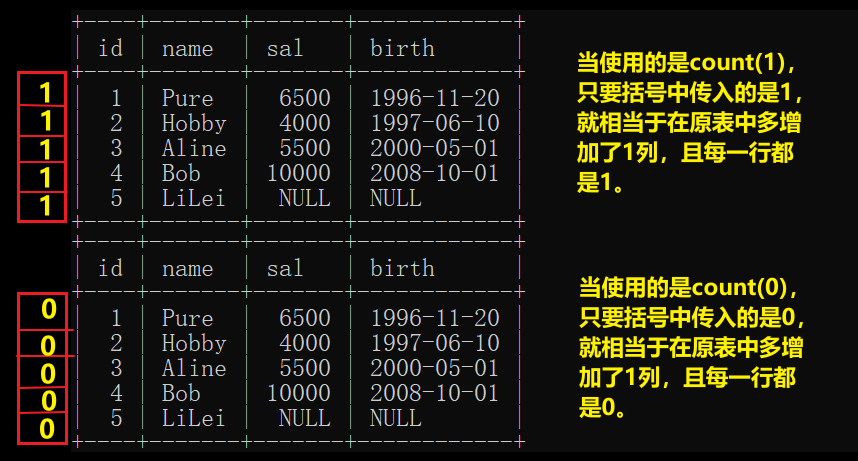
count(1),count(0),count(*),count(列名)的区别
count(0),count(1),count(*)不会过滤空值
count(列名)会过滤空值
无论是sum(1),sum(0),count(1),count(0),avg(1),avg(0),原理都是一样的,
相当于在原表中新增一列。
其次,我们知道where后面接的是逻辑值,当使用where 1和where 0原理也还是
一样,也相当于在原表中新增一列。
我们只需要记住在mysql中:非0即为true,0为false。也就是说,下面的所有是
1的地方,你可以换成任何非0数字,都是可以的。
count(1),count(0)原理图如下:
测试结果:
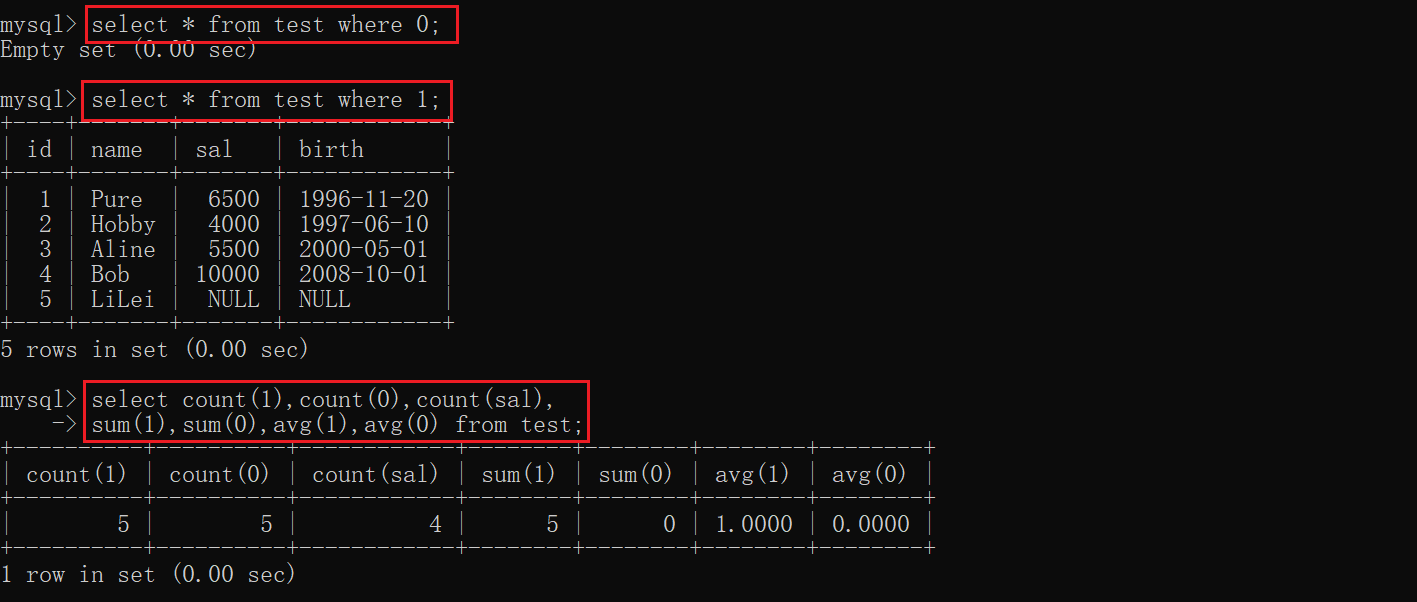
count(*),count(1)计数的效率问题
- MYISAM存储引擎下,count(*)的效率高。
- INNODB存储引擎下,count(*)和count(1)的效率差不多,比count(字段)效率要高一些。
- 综上所述:优先使用count(*)。
聚合函数和group by的联合使用
关于这个知识点,我们将会在后面的知识点中进行讲述。在这里我们只需要记住一句话:当SQL语句中使用了group by分组函数后,select后面的字段必须是group by后面的字段 + 聚合函数的使用。
其它常用系统函数