《MySQL面试小抄》索引考点二面总结
我是肥哥,一名不专业的面试官!
我是囧囧,一名积极找工作的小菜鸟!
囧囧表示:小白面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点!!!
本期主要面试考点
- 面试官考点之谈谈索引维护过程?页分裂?页合并?
- 面试官考点之简述一下查询时B+树索引搜索过程?
- 面试官考点之什么是回表?
- 面试官考点之什么是索引覆盖?使用场景?
- 面试官考点之什么情况下会索引失效?
- 面试官考点之哪些情况下,可能会面临索引失效的问题?
- 面试官考点之or走索引和索引失效分别是什么场景?
- 面试官考点之哪些情况下需要创建索引?
- 面试官考点之联合索引之最左前缀原则?
- 面试官考点之索引下推场景?


面试官考点之谈谈索引维护过程?页分裂?页合并?
B+树为了维护索引有序性,在插入删除的时候需要做必要的维护,必要时候可能涉及到页分裂,页合并过程!
首先假设每个叶子节点(数据页或磁盘块)只能存储3条索引和数据记录,如图
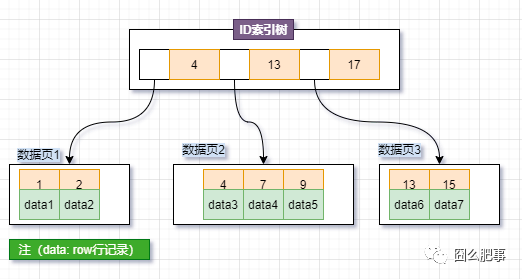
情况1、新增行记录,ID=3,此时【数据页1】未满,只需要在data2后新增ID=3的行记录,B+树整体结构不需要进行调整
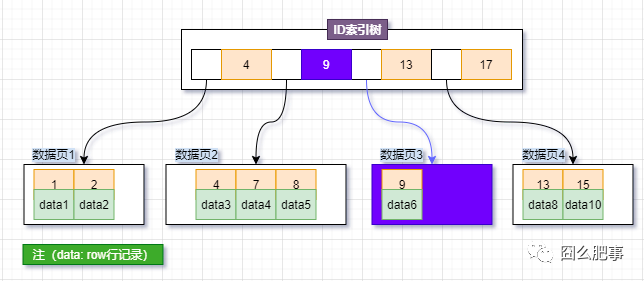
情况2、新增行记录,ID=8,此时【数据页2】已满,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。
页分裂过程消耗性能,同时空间利用率也降低了
有分裂就有合并,当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
【数据页2】删除了ID=7,ID=8的行记录,此时【数据页2】【数据页3】利用率很低,将进行页合并。
面试官考点之简述一下查询时B+树索引搜索过程?
准备一张用户表,其中id为主键,age为普通索引
- CREATE TABLE `user` (
`id` int(11) PRIMARY KEY,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
select * from user where age=22 简述一下B+树索引搜索过程?
假设要查询的记录
- id=5,name="张三",age=22
MySQL为每个索引分别维护了一棵B+Tree索引树,
主键索引非叶子节点维护了索引键,叶子节点存储行数据;
非主键索引也称为二级索引,非叶子节点存储主键;
B+树索引搜索过程
搜索条件 age=22,可走idx_age索引,首先加载idx_age索引树,找到age=22的记录,取得id=5
回表搜索,加载主键索引树,找到id=22的记录,取得整行数据
面试官考点之什么是回表?
idx_age二级索引树找到主键id后,回到id主键索引搜索的过程,就称为回表。
并非所有非主键索引搜索,都需要进行回表搜索,也就是下面要说的索引覆盖。
面试官考点之什么是索引覆盖?使用场景?
在上面提到的例子中,由于查询结果所需要的数据只在主键索引上有,所以不得不回表。
如果在查询的数据列里面,直接从索引列就能取到想要的结果,就不需要再回表去查,也称之为索引覆盖!
索引覆盖的优点
-
可以避免对Innodb主键索引的二次查询
-
可以避免MyISAM表进行系统调用
-
可以优化缓存,减少磁盘IO操作
修改一下上述栗子,满足索引覆盖条件?
- select id, age from user where age=22
查询的信息,id,age都可以直接在idx_age 索引树中获取,不需要回表搜索。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用 的性能优化手段。
索引是一把双刃剑,提供快速排序搜索的同时,索引字段的维护也是要付出相应的代价的。
因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑了
面试官考点之索引失效?
创建的索引,到底有没有生效,或者说SQL语句有没有使用索引查询?
一个最常见的查询场景,建立idx_name索引
- select * from t_user where user_name like '%mayun100%';
这条查询是否走索引?

- select * from t_user where user_name like 'mayun100%';
这条查询是否走索引?

面试官考点之有哪些情况下,可能会面临索引失效的问题?
-
like通配符,左侧开放情况下,全表扫描
-
or条件筛选,可能会导致索引失效
-
where中对索引列使用mysql的内置函数,一定失效
-
where中对索引列进行运算(如,+、-、*、/),一定失效
-
类型不一致,隐式的类型转换,导致的索引失效
-
where语句中索引列使用了负向查询,可能会导致索引失效 负向查询包括:NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等。其中!< !> 为SQLServer语法。
-
索引字段可以为null,使用is null或is not null时,可能会导致索引失效
-
隐式字符编码转换导致的索引失效
-
联合索引中,where中索引列违背最左匹配原则,一定会导致索引失效
-
MySQL优化器的最终选择,不走索引
面试官考点之or走索引和索引失效分别是什么场景?
or走索引和索引失效分别是什么场景?

OR 连接的是同一个字段,相同走索引
- explain select * from t_user where user_name = 'mayun10' or user_name = 'mayun1000'

OR 连接的是两个不同的字段,不走索引

给address列增加索引
- alter table t_user add index idx_address(address);
explain select * from t_user where user_name = 'mayun10' or address = '浙江杭州12';
OR 连接的是两个不同字段,如果两个字段皆有索引,走索引

(插播,下一期:《MySQL面试小抄》几种索引失效场景验证)
尽请关注:囧么肥事
面试小抄系列。
面试官考点之哪些情况下需要创建索引?
1.主键自动建立唯一索引
2.频繁查询的字段
3.JOIN 关联查询,作为外键关系的列建立索引
4.单键/组合索引的选择问题,高并发下倾向创建组合索引,创建时遵循最左前缀匹配原则
5.ORDER BY 查询中排序的字段,排序字段通过索引访问大幅提高排序速度
6.GROUP BY 需要分组字段或查询中统计字段
面试官考点之联合索引之最左前缀原则
MySQL建立多列索引(联合索引)有最左前缀的原则,即最左优先
当MySQL建立的是联合索引,假设以(a,b,c) 列作为联合索引,那么MySQL建树规则是什么?
我们知道MySQL会为每一个索引维护一颗B+Tree,非叶子节点存储索引key,叶子节点存储行数据data。
联合索引(a,b,c) 相当于建立了 (a), (a,b), (a,b,c) 三个索引,MySQL组装索引树时,是按照从左到右的顺序来建立B+Tree的联合索引树的。
匹配索引情况一
假设(a,b,c)索引要搜索的值为('张三', 21, 100) ,检索数据时,匹配的顺序就是a,b,c。
B+Tree会优先比较a来确定下一步的所搜方向,如果a相同再依次比较b和c,最后得到检索的数据;
匹配索引情况二
假设(a,c)索引要搜索的值为('张三', 100) ,检索数据时,匹配的顺序就是a,b,c。
B+Tree使用a来指定搜索方向,但下一个字段b缺失,所以只能把a等于张三的数据都找到,然后再匹配c是100的数据。
匹配索引情况三
假设(b,c)索引要搜索的值为('张三', 21) ,检索数据时,无匹配顺序
B+Tree不知道下一步该查哪个节点,因为建立搜索树的时候a是第一个比较因子,必须要先根据a来搜索才能知道下一步去哪里查询。此时索引失效!
索引项是按照索引定义里面出现的字段顺序排序的,最左前缀可以是联合索引的最左N个字段,也可以是字符串索引的最左M个字符。
面试官考点之索引下推场景?
索引下推,即减少二级索引回表搜索次数!!!
通俗说,减少查询主键索引树次数,减少磁盘IO
建立联合索引 idx_age_weight
- select * from user where age = 11 and weight = 98
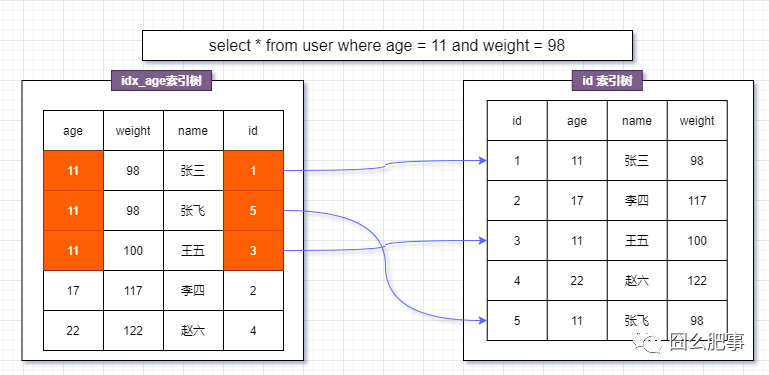
5.6之前搜索过程是
在idx_age_weight 索引树中匹配出所有的 age = 11 索引,拿到主键id,回表去一条条再比对weight字段
如下图,需要进行3次回表搜索操作
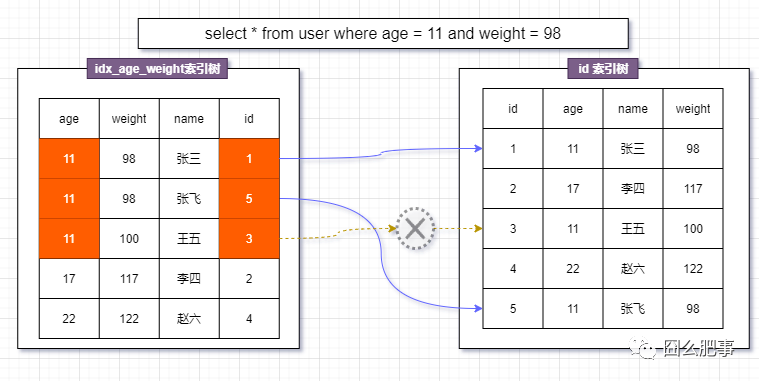
5.6后的搜索过程是 在idx_age_weight 索引树中匹配出所有的 age = 11 索引,顺便对weight字段进行判断,过滤掉weight = 100的记录,然后再进行回表搜索。
如下图,只需要进行2次回表搜索操作
随缘更新,大神请绕路!
更多精彩内容,欢迎关注微信公众号:囧么肥事 (或搜索:jiongmefeishi)
