说起Excel,那绝对是数据处理领域王者般的存在。
而作为网红语言Python,在数据领域也是被广泛使用。
其中Python的第三方库-xlwings,一个Python和Excel的交互工具,可以轻松地通过VBA来调用Python脚本,实现复杂的数据分析。
今天,小F就给大家介绍一个Python+Excel的项目【视频下载器】。

主要使用到下面这些Python库。
- import os
- import sys
- import ssl
- import ffmpeg
- import xlwings as xw
- from pathlib import Path
- from aip import AipSpeech
- from pydub import AudioSegment
- from wordcloud import WordCloud
- from pydub.utils import make_chunks
- from moviepy.editor import AudioFileClip
其中ffmpeg、pydub、moviepy是用来处理音视频的,比如裁剪、格式转换等。
aip库则是百度官方库,用来做语音转文字的。
- # 安装
- pip install baidu-aip
对于xlwings这里就不多说了,想了解的小伙伴,可以去看官方文档。
地址:https://docs.xlwings.org/en/stable/
下面就给大家来介绍一下吧!
首先调用xlwings模块生成一个项目,命令如下。
- # 创建项目
- xlwings quickstart transcriber --standalone
这时候我们就能看到有一个项目名称为transcriber的文件夹,这个就是作为我们项目使用的,并且可以修改为任何名字。

其中注意:
1. transcriber.py,这是带Python代码的文件,内容如下。
- import xlwings as xw
-
- def main():
- wb = xw.Book.caller()
- sheet = wb.sheets[0]
- if sheet["A1"].value == "Hello xlwings!":
- sheet["A1"].value = "Bye xlwings!"
- else:
- sheet["A1"].value = "Hello xlwings!"
-
- @xw.func
- def hello(name):
- return f"Hello {name}!"
-
- if __name__ == "__main__":
- xw.Book("transcriber.xlsm").set_mock_caller()
- main()
2. transcriber.xlsm,这是带vba代码的Excel文件,内容如下。
打开Excel文件,提示没有启用宏,所以设置一下。
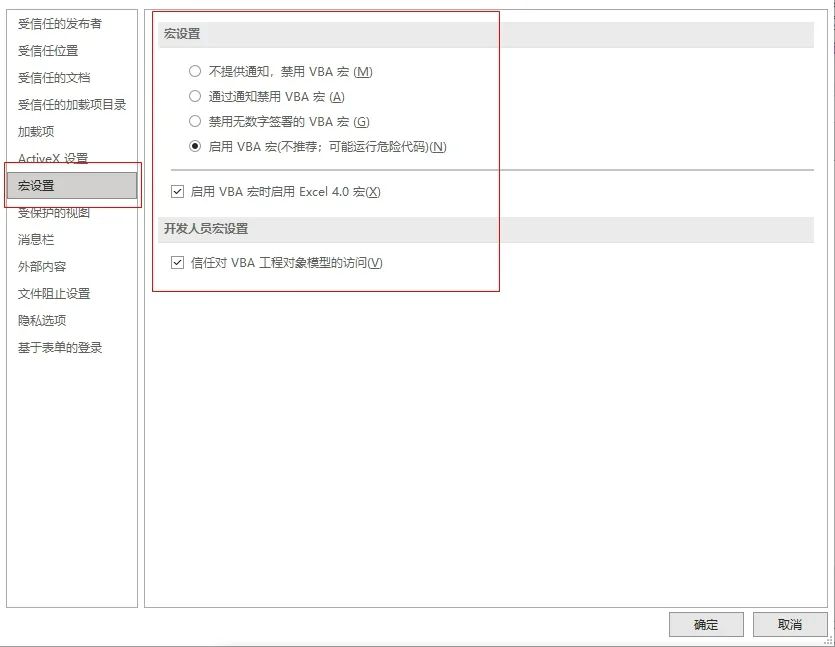
文件 - 更多 - 选项 - 信任中心 - 信任中心设置 - 宏设置 - 启用所有宏。
然后安装xlwings的Excel集成插件,安装之前需要关闭所有Excel应用,不然会报错。
- # 安装xlwings的Excel集成插件
- xlwings addin install
xlwings和插件都安装好后,这时候打开Excel,会发现工具栏出现一个xlwings的菜单框,代表xlwings插件安装成功。
它起到一个桥梁的作用,为VBA调用Python脚本牵线搭桥。
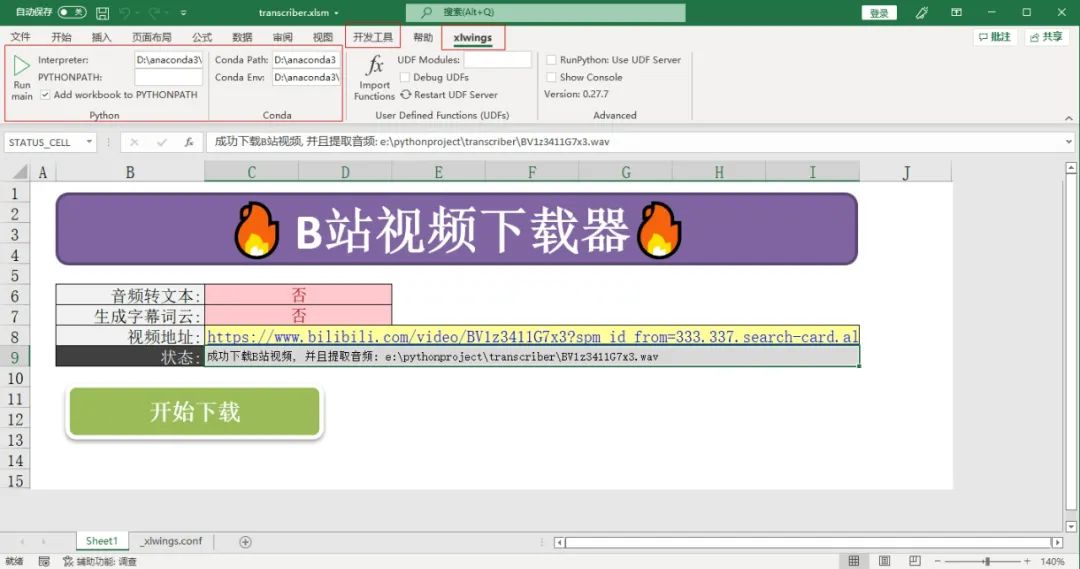
此外还需要把“开发工具”添加到功能区,因为我们要用到宏。
配置运行环境,Python执行器,Conda安装路径,Conda虚拟环境路径。
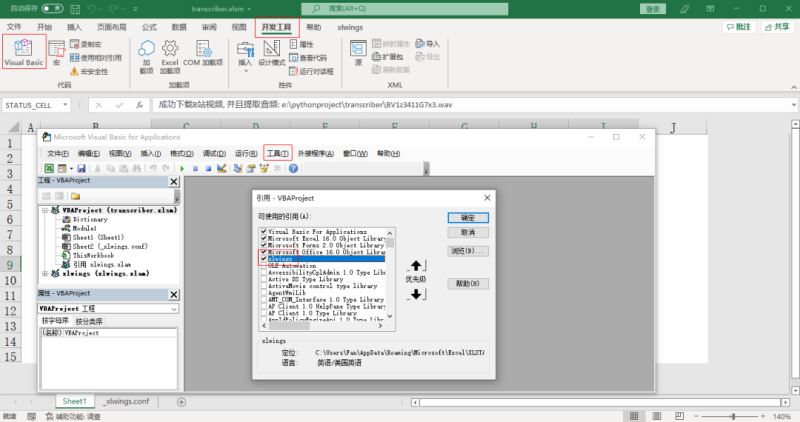
最后点击“开发工具”选项卡,点击Visual Basic - 工具 - 引用 - 添加xlwings。
到此,环境就配置成功了。
我们先用之前创建的transcriber.xlsm文件来实验一下,插入一个按钮,指定宏。
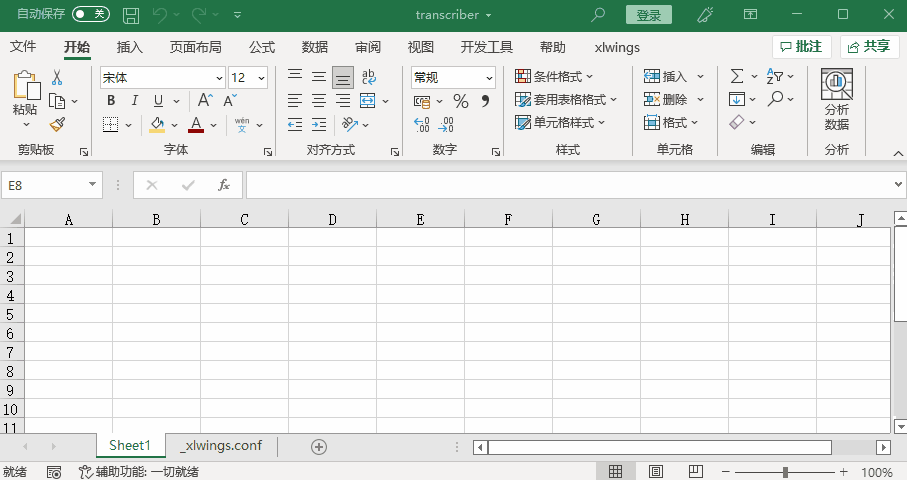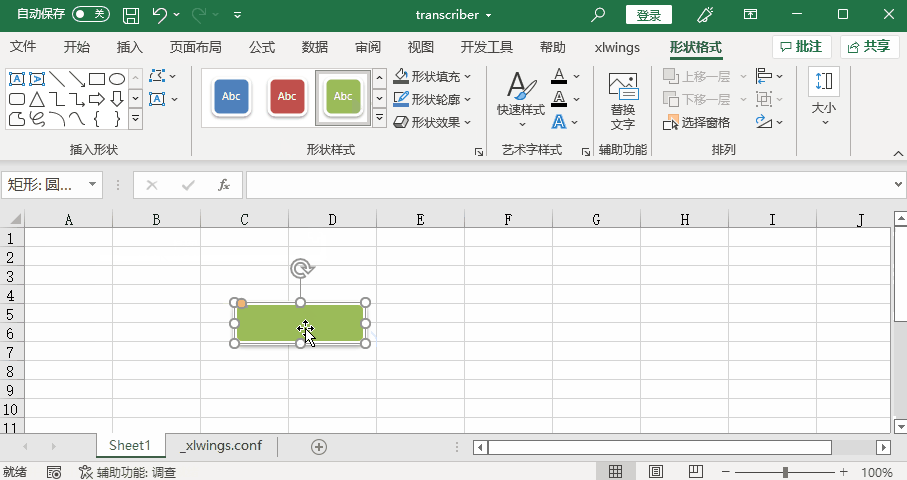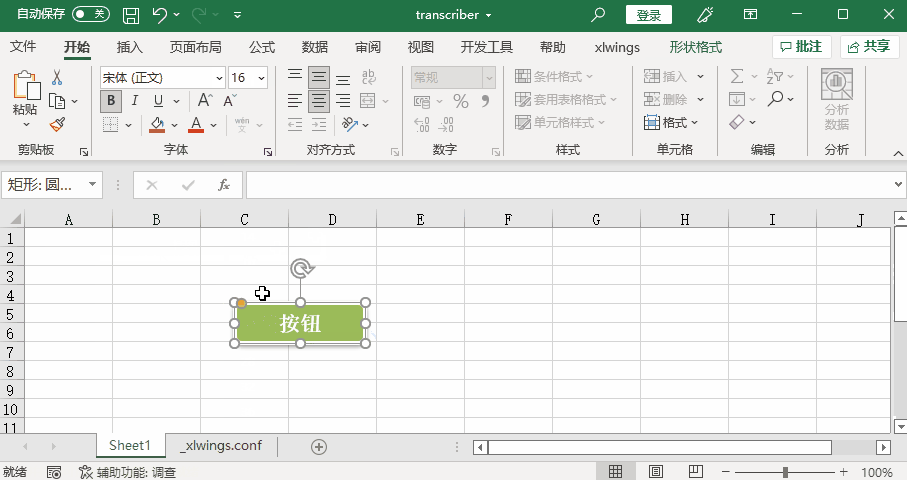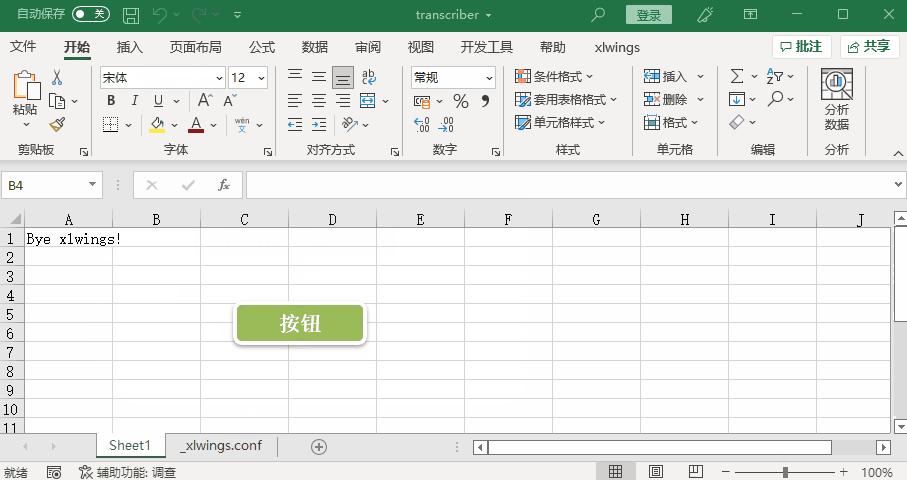
点击绿色的按钮,可以看见A1单元格会有信息出现,说明启用宏成功。
这里我们可以把A1单元格名称修改为OUTPUTCELL。
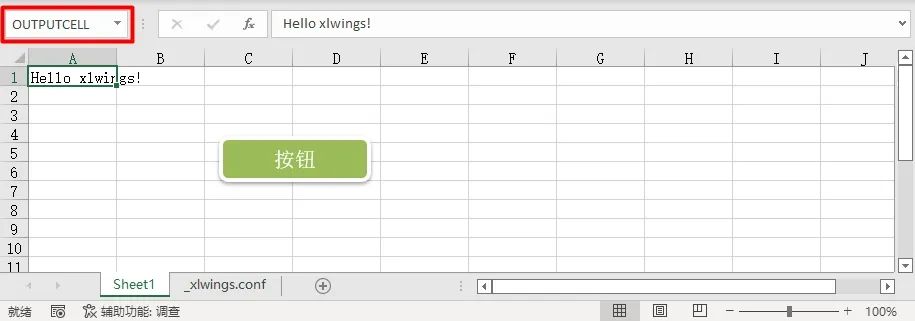
再去修改transcriber.py文件中的代码。
- import xlwings as xw
-
- def main():
- wb = xw.Book.caller()
- sheet = wb.sheets[0]
- if sheet["OUTPUTCELL"].value == "Hello":
- sheet["OUTPUTCELL"].value = "Bye"
- else:
- sheet["OUTPUTCELL"].value = "Hello"
-
- @xw.func
- def hello(name):
- return f"Hello {name}!"
-
- if __name__ == "__main__":
- xw.Book("transcriber.xlsm").set_mock_caller()
- main()
点击按钮,发现信息有所变,说明可以给单元格指定名称和输出。
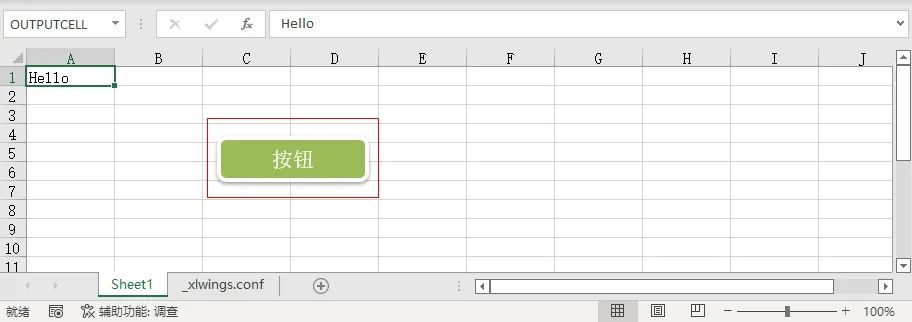
了解了xlwings的基本使用,我们就可以对表格进行排版布局一波啦!

给音频转文本,生成字幕词云添加数据验证,其实就是一个列表选项,可选择是或否。
给音频转文本,生成字幕词云添加条件格式,选择是或否后,展示不同的颜色,默认否(淡红色)。

好了,最后修改一下各个单元格的名称。
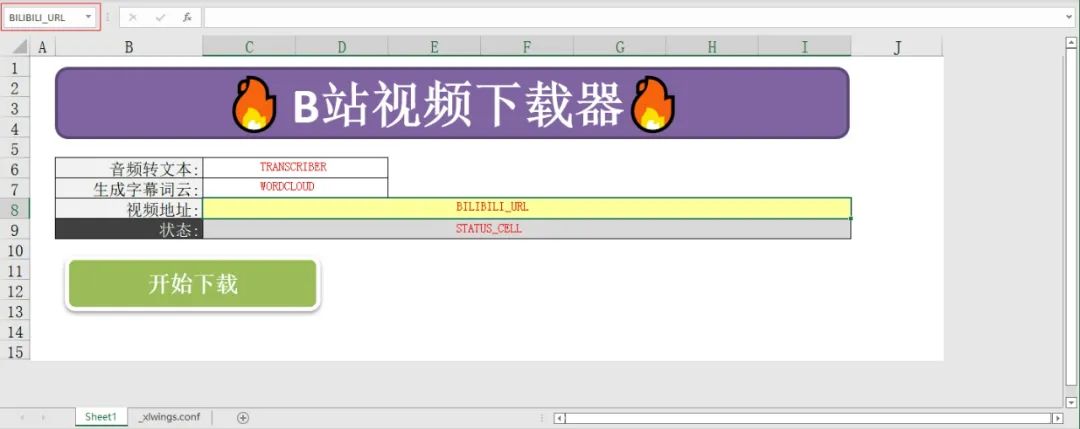
编写主程序,代码如下。
- def main():
- wb = xw.Book.caller()
- sheet = wb.sheets[0]
-
- bilibili_url = sheet["BILIBILI_URL"].value
- transcribe = sheet["TRANSCRIBE"].value
- wordcloud = sheet["WORDCLOUD"].value
- status_cell = sheet["STATUS_CELL"]
-
- # 重置状态栏
- status_cell.value = ""
-
- # 获取程序运行路径
- output_path = Path(__file__).parent
- output_path = str(output_path)
-
- # 下载
- if bilibili_url:
- status_cell.value = "开始下载音视频文件 ..."
- audio_file = download_bilibili(bilibili_url, status_cell, output_path)
- else:
- status_cell.value = "未输入B站视频地址"
- sys.exit()
-
- # 语音转文字
- if transcribe == '是':
- transcription_text = transcribe_audio_file(status_cell, audio_file, output_path)
-
- # 生成词云
- if transcribe == '是' and wordcloud == '是':
- generate_wordcloud(transcription_text, output_path, status_cell)
使用第一个sheet表,不断的更新状态栏信息,判断是否要运行下载、语音转文字、生成词云这三个函数。
下载音视频使用到了you-get库,一键下载几乎所有网站上的音视频。
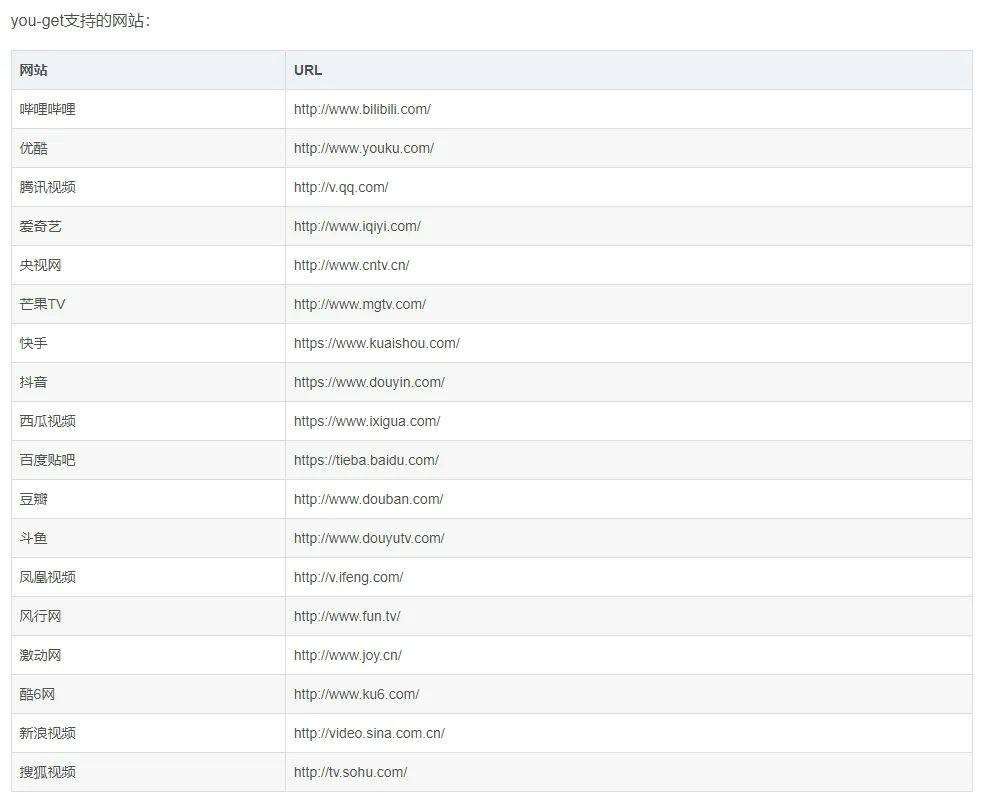
支持的网站还不少呢,本次就只用B站的视频来测试。
- def download_bilibili(bilibili_url, status_cell, output_path):
- """下载音视频"""
- filename = bilibili_url.split('/')[-1].split('?')[0]
- cmd = 'you-get {} -o {} -O {}'.format(bilibili_url, output_path, filename)
- os.system(cmd)
-
- # 导入视频
- my_audio_clip = AudioFileClip(output_path + "\\{}.flv".format(filename))
-
- # 提取音频并保存
- audio_file = output_path + "\\{}.wav".format(filename)
- my_audio_clip.write_audiofile(audio_file)
-
- status_cell.value = f"成功下载B站视频, 并且提取音频: {audio_file}"
- return audio_file
使用moviepy库提取视频中的音频,用于语音识别。
当音频转文本选项的内容是【是】的时候,下面代码就派上用场了。
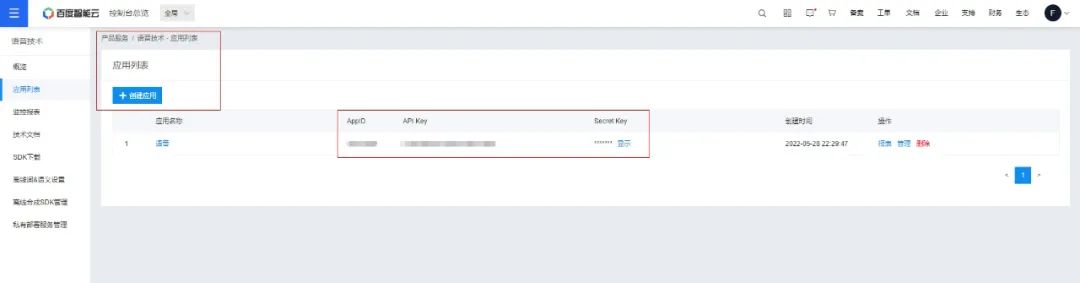
使用百度的短语音识别技术,需要申请使用,不想用的小伙伴直接两个可选项选择【否】,当做一个下载器即可。
可惜识别最长时间只能是60秒,所以需要将之前获取的音频进行切割。
此外还需要对音频的采样率进行匹配。
- def transcribe_audio_file(status_cell, audio_file, output_path):
- """语音转文字"""
- status_cell.value = "开始处理音频文件..."
- old_name = audio_file
- new_name = audio_file.split('.')[0] + '_16000.wav'
- split_name = audio_file.split('.')[0]
- # 对音频进行降频处理
- ffmpeg.input(old_name).output(new_name, ar=16000).run(cmd=FFMPEG_PATH)
-
- # 切割音频
- audio = AudioSegment.from_file(new_name, "wav")
- # 切割的毫秒数
- size = 30000
- # 将文件切割为30s一块
- chunks = make_chunks(audio, size)
- for i, chunk in enumerate(chunks):
- # 枚举,i是索引,chunk是切割好的文件
- chunk_name = split_name + "_{0}.wav".format(i)
- # 保存文件
- chunk.export(chunk_name, format="wav")
-
- status_cell.value = "使用百度语音接口识别音频..."
- # 使用百度语音接口
- """ 你的 APPID AK SK """
- APP_ID = ''
- API_KEY = ''
- SECRET_KEY = ''
-
- client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
-
- # 读取文件
- def get_file_content(file_path):
- with open(file_path, 'rb') as fp:
- return fp.read()
-
- transcription_txt = output_path + "\\transcription.txt"
-
- # 识别本地文件
- for i, chunk in enumerate(chunks):
- result = client.asr(get_file_content(split_name + "_{0}.wav".format(i)), 'wav', 16000, {
- 'dev_pid': 1537 # 默认1537(普通话 输入法模型),dev_pid参数见本节开头的表格
- })
-
- print(result['result'])
- with open(transcription_txt, "a") as file:
- file.write(result['result'][0])
- file.close()
-
- status_cell.value = f"音频转文本成功, 文件保存到 {transcription_txt}"
- return transcription_txt
可识别普通话、英语、粤语、四川话识别。通过在请求时配置不同的dev_pid参数,选择对应模型。
最终将音频转为文本,保存在一个文本文件中。
生成词云,这里需要注意添加中文字体路径,要不然词云图显示不了中文。
- def generate_wordcloud(textfile, output_path, status_cell):
- """生成词云"""
- textfile = Path(textfile)
- content = textfile.read_text()
- wordcloud = WordCloud(font_path=output_path + '\\simhei.ttf').generate(content)
- wordcloud.to_file(Path(output_path) / f"{textfile.stem}.png")
- status_cell.value = "生成词云图"
项目整体就如上面描述的一样。
此时我们只需打开Excel文件,选择是或否选项,修改B站视频地址,点击开始下载,即可下载视频,以及生成词云图。
无需再去运行Python文件。

成功下载到视频,并且对音视频进行处理,得到文本信息。

查看一下词云图吧。

发现百度的语音识别有点差啊,不知道是哪里出现了问题...
以上就是利用Python+Excel制作一个视频下载器的详细内容,更多关于Python Excel视频下载器的资料请关注w3xue其它相关文章!
