select @a;
变量名,如果你不加的话,会认为这是一个列名,但是这列不存在,就报错了;
- @变量名 : 定义一个用户变量.
- = 对该用户变量进行赋值.
用户变量赋值有两种方式: 一种是直接用"=“号,另一种是用”:=“号。
其区别在于:
- 使用set命令对用户变量进行赋值时,两种方式都可以使用;
- 用select语句时,只能用”:=“方式,因为select语句中,”="号被看作是比较操作符。
(@i:=@i+1)
可以在生成查询结果表的时候生成一组递增的序列号
select (@i:=@i+5) as rownum, surname, personal_name from student, (select @i:=100) as init;
select @ids := 101,@l := 0
GROUP_CONCAT + group by
按照分组,连接字段上的数据,默认以,,也可以指定分割符
mysql的@用法
1,增加临时表,实现变量的自增
- SELECT (@i:=@i+1),t.* FROM table_name t,(SELECT @i:=0) AS j
(@i:=@i+1)代表定义一个变量,每次叠加1;
(SELECT @i:=0) AS j 代表建立一个临时表,j是随便取的表名,但别名一定要的。
2,实现排序递增
- SELECT
- ( @i := @i + 1 ),
- p.*
- FROM
- ( SELECT * FROM sys_region ORDER BY create_time DESC ) p, ( SELECT @i := 0 ) k
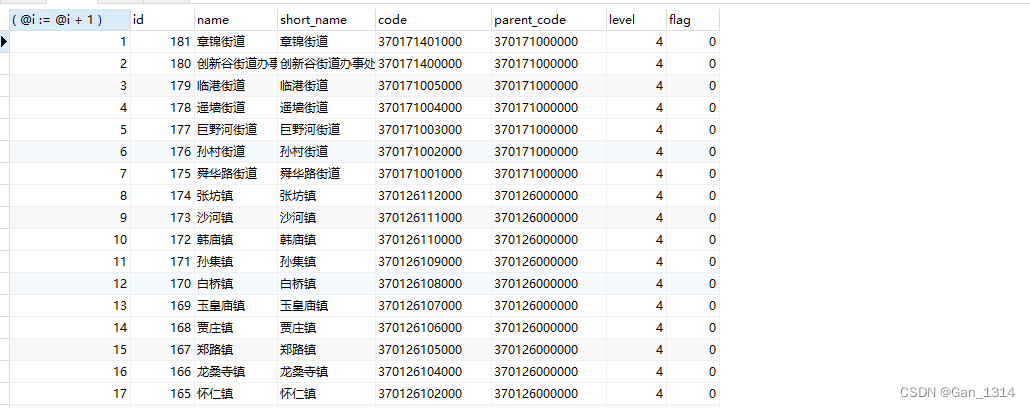
3,实现分组递增
- SELECT
- @r := CASE WHEN @type = a.LEVEL THEN
- @r + 1
- ELSE
- 1
- END AS rowNum,
- @type := a.`level` AS type,
- a.id
- FROM
- sys_region a,( SELECT @r := 0, @type := '' ) b;
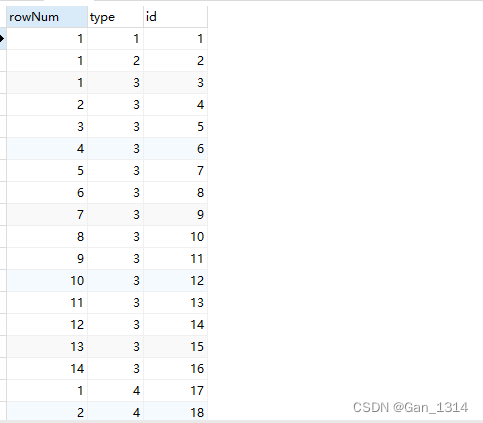
这里用了临时变量@type,因为对临时变量操作的时候,被使用的变量都是临时变量。
实战
- INSERT INTO t_top ( col_account, col_date, p_account, p_name )
-
- SELECT b.col_account, b.col_date, b.p_account, b.p_name FROM
- (
- SELECT
- @num := CASE WHEN @account = a.col_account THEN
- @num + 1
- ELSE
- 1
- END AS rownum,
- @account := a.col_account AS account,
- a.*
- FROM
- ( SELECT * FROM zb_top ORDER BY col_account, p_avg DESC ) a,
- ( SELECT @num := 0, @account := '' ) j
- ) b where 6 > b.rownum
计算用户距上次访问的天数,根据imei号区分不同的用户,如果时间段内只有一次访问则为0。
初始化数据:
代码示例:
- CREATE TABLE `pd` (
- `imei` varchar(32) NOT NULL DEFAULT '',
- `date` datetime DEFAULT NULL
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-
- INSERT INTO `pd` VALUES ('1', '2013-07-25 00:00:01');
- INSERT INTO `pd` VALUES ('1', '2013-07-26 00:00:02');
- INSERT INTO `pd` VALUES ('2', '2013-07-23 00:00:04');
- INSERT INTO `pd` VALUES ('2', '2013-07-26 00:00:03');
- INSERT INTO `pd` VALUES ('3', '2013-07-26 00:00:01');
脚本,使用@特殊变量:
代码示例:
- SELECT * FROM
- (
- SELECT
- imei user_id,
- max(max_dd),
- max(max_dd_2),
- to_days(max(max_dd)) - to_days(max(max_dd_2)) days
- FROM
- (
- SELECT
- imei,
- max_dd,
- max_dd_2
- FROM
- (
- SELECT
- tmp.imei,
- tmp.date,
- IF(@imei = tmp.imei, @rank := @rank + 1, @rank := 1) AS ranks,
- IF(@rank = 1, @max_d := tmp.date, @max_d := NULL) AS max_dd,
- IF(@rank = 2, @max_d_2 := tmp.date, @max_d_2 := NULL) AS max_dd_2,
- @imei := tmp.imei
- FROM
- (SELECT imei, date FROM pd ORDER BY imei ASC, date DESC) tmp,
- (SELECT @rownum := 0, @imei := NULL, @rank := 0, @max_d := NULL, @max_d_2 := NULL) a
- ) result
- ) t
- GROUP BY
- imei
- HAVING
- count(*) > 1
- ) x WHERE x.days >= 1 AND EXISTS (SELECT 'x' FROM pd WHERE date > '2013-07-26 00:00:00')

注意:
表数据量较大时,使用union all等操作将会有悲剧性的结果。
到此这篇关于MySQL中符号@的作用的文章就介绍到这了,更多相关MySQL 符号@内容请搜索w3xue以前的文章或继续浏览下面的相关文章希望大家以后多多支持w3xue!
