续上篇:https://www.cnblogs.com/techs-wenzhe/p/12936809.html
第一步中已经提取出了源视频的人脸照片以及对应人脸遮罩(landmark以及其他自选遮罩)
第二步:利用Tools处理提取号好的数据集,使其对模型的训练产生正向收益。
步骤1:剔除不需要的人脸
首先,我们需要剔除不需要的人脸(对齐识别错误以及非想要换脸的目标),做法是对生成的人脸进行聚类,排序。之后把不需要的类别的人脸删除掉。
这一步的目的是:我们都知道训练一个模型输入参数的正确性决定了算法的精确度,这一步就是为了去除所有错误的,不恰当的输入数据(图片)集。我们需要给模型一个清晰,明了的可学习对象。
PS:如果你的输入数据集(人脸图片很多)过大,请拆分成多个,需要分多次聚类排序。因为这些操作会在RAM中进行,例如:大约22k 张人脸对应大约8G RAM,30k对应11G(还要考虑其他内存使用,浏览器什么的==). 根据你电脑的RAM能力,选择分几次来处理即可。
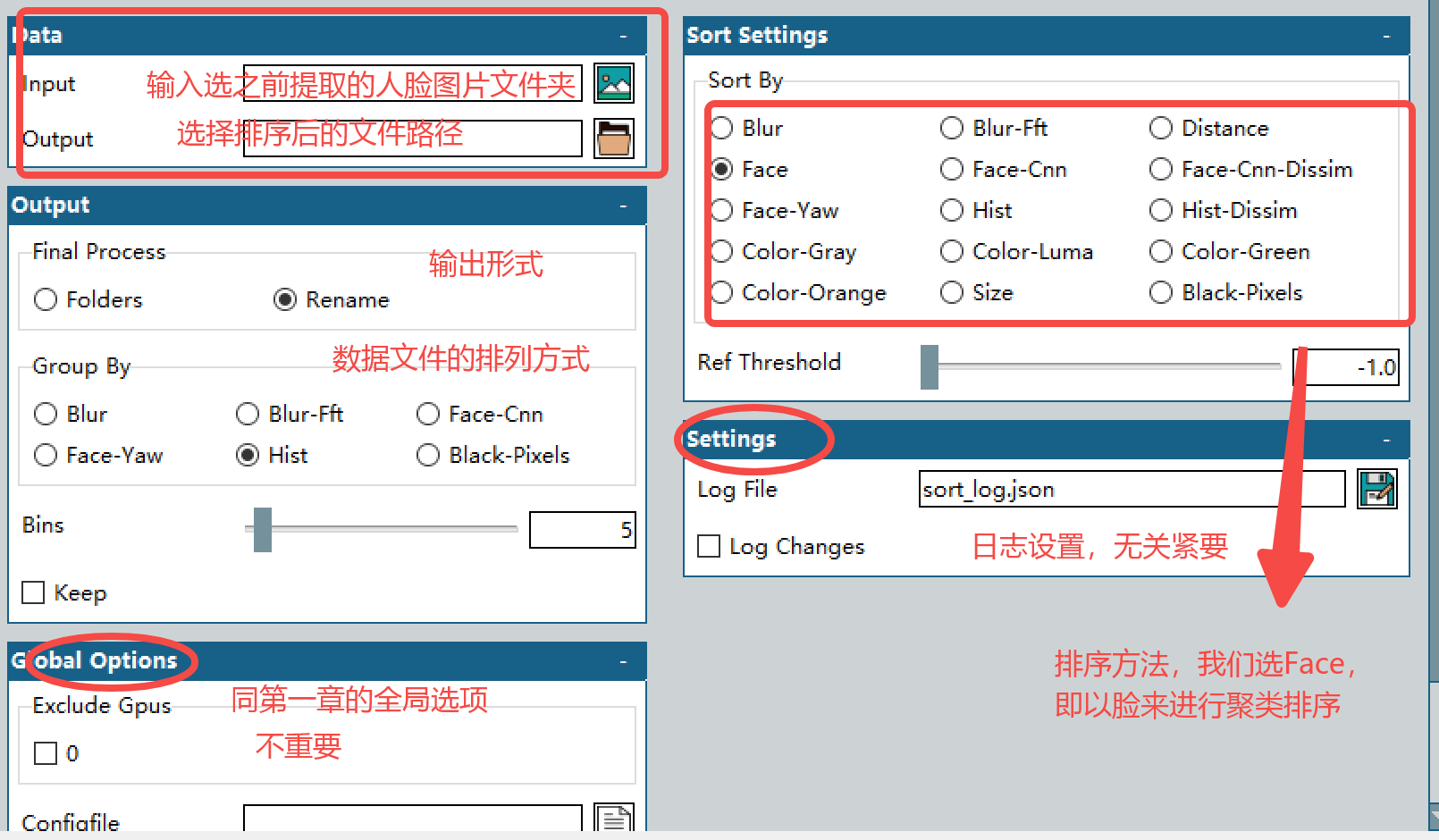
GUI的设置如下:
PS: 实际根据有啥模型就用啥,笔者自己办公用的机器有Face-cnn,所以就选了用这个模型排序,选face的话得需要vggface2_resnet50_v2.zip模型在对应目录下才行。

1.1 Data模块:
-
Input:输入包含上一步提取的人脸的文件夹。
-
Output:留空则基于输入的文件内直接排序。
1.2 Sort Settings模块:
-
Sort by:排序的方式,这里直接选face即可。意思是根据人脸相似度进行排序。当然还有其他排序方式(如基于landmark的Face-CNN,基于模糊度的Blur,基于聚类距离-识别错误对齐的distance,基于颜色的Color系列,基于大小的Size系列),实测还是face最有效。
-
Ref Threshold:Sort by内特殊几种算法(face-CNN, Hist)的调节,同样的值越高越严格。(推荐设置为-1即可,代表自动设置默认值) ,face-CNN 7.2就足够了,设置为4会有较高识别度。Hist 0.3就足够,设置为0.2 会有较高的识别度
1.3 Output模块:这里不需要设置任何东西(此部分已完全弃用,并将在未来的更新中删除。这里不需要设置任何东西。
选好模型,选好数据集(图片)所在文件夹,选好输出文件夹,点击sort等待结果即可。

可看到是提取图片中的landmark,根据直方图分类。

一旦完成,你应该发现 99% 的面孔被分类在一起,所有垃圾也一起分类,现在只需浏览每个垃圾箱(子文件夹),删除那些您不想保留的面孔/文件夹,然后将您想要保留的任何面孔移回父文件夹。
至此,排序完毕,接下来要清理对齐-alignments文件
步骤2:清理对齐文件
现在我们已经删除了所有不需要的面孔,只剩下一组了,接下来要做的是清理对齐文件(对齐文件中包含了每张图片对应的五官所在位置的数据)。因为所有关于不需要的面孔的信息仍然在文件中(刚才排序步骤删除的那些),这很可能在将来给我们带来麻烦。所以需要删除不需要图片的对齐文件。 使用集成工具清理对齐文件还有一个额外的好处,可以将我们的面孔重命名回它们的原始文件名。
步骤如下,找到Tools->Alignments文件:

根据上图设置后,点击alignments,完成后面孔将被重新命名为默认名称,并且所有不需要的面孔就会从对齐文件中删除。
该过程将备份旧对齐文件并将其放在新创建的文件旁边的原始位置。它将与您清理过的对齐文件同名,但在其末尾附加“backup_<timestamp>”。如果对新的对齐文件正确无误感到满意,则可以安全地删除此备份文件。
此时,如果正在提取以进行转换(或者该集合将用于转换和训练),那么可以完全删除faces 文件夹。不再需要这些面孔。如果您需要重新生成面部集,则可以使用对齐工具的extract来完成。
执行完对齐文件的清理后,留下来的对齐文件就是想要训练的有效数据集(脸)对应的对齐文件了。
现在已经清理了对齐文件,需要拉出其中的一些脸用于作为训练集。
导航到工具选项卡,然后导航到对齐子选项卡:
完成后,将所有人脸数据集放入同一个文件夹中。训练集已准备就绪。后续第三章将介绍训练部分。
——————————————活在当下,首先就是要做好当下的事.
