
我们都知道天下没有“永不宕机”的系统,但每次线上出问题都要拉出一个程序员“祭天”。所以一款靠谱、好用的监控工具就显得十分重要,它可以在生产环境出故障的第一时间发出告警,并提供详实的数据,帮助程序员尽早发现故障、尽快定位问题。
可以毫不夸张地说:监控就是运维的眼睛、研发的“免死金牌”,程序员“明哲保身、自证清白”的必备利器!
一、夜莺监控
今天 HelloGitHub 给大家带来的是一款开箱即用、默认中文、界面美观的开源监控系统——夜莺监控(Nightingale),100% 国产更懂你的苦。你还在为搭建/配置/调优「Prometheus + AlertManager + Grafana」的监控平台而烦恼吗?开箱即用的夜莺监控轻松解决你的问题。
GitHub:https://github.com/ccfos/nightingale
夜莺监控是一款先进的开源云原生监控分析系统,采用 All-In-One 的设计,集数据采集、可视化、监控告警、数据分析、权限管理于一体,拥有企业级的监控分析和告警能力。
夜莺监控在运维圈里很有名,它“出身名门”最初是由滴滴孵化并开源,在此期间沉淀了一线互联网公司可观测性的最佳实践,有大厂的实践背书可靠性和实用性上毋庸置疑。之后则捐赠给了中国计算机学会(CCF)进行托管,由运维圈的“老炮”秦晓辉等人设计、开发和维护。截止到发文前,夜莺监控已在 GitHub 上获得了 7200+ 个 Star、1200+ 次 Fork,发展势头迅猛、开源社区活跃,并且已经服务了上千家分布在各行各业的企业。

接下来,就和 HelloGitHub 一起上手这款开箱即用的开源监控利器吧!
二、安装启动
最简单的部署方式是使用 docker-compose,可实现一键启动,执行下面的命令即可:
git clone https://github.com/ccfos/nightingale.gitcd nightingale/dockerdocker-compose up -d# 成功后会有以下输出# Creating mysql ... done# Creating redis ... done# Creating prometheus ... done# Creating ibex ... done# Creating agentd ... done# Creating n9e ... done# Creating telegraf ... done
启动之后浏览器直接访问:127.0.0.1:17000,输入账号 root 密码:root.2020,登陆后就能看到管理界面啦!

不过,我还是更推荐大家使用二进制方式部署,因为这种方式不依赖 Docker、更稳定、升级也方便,可用于生产环境(官方推荐),部署起来也不麻烦,也就多几行命令的事。下面是 linux x86 环境的示例和注解:
# 创建个 n9e 的目录,后面把 n9e 相关的文件解压到这里mkdir -p /opt/n9e && cd /opt/n9e# 下载 n9e 发布包,amd64 是 x84 的包,下载站点也提供 arm64 的包,如果需要其他平台的包则要自行编译了tarball=n9e-v6.1.0-linux-amd64.tar.gzurlpath=https://download.flashcat.cloud/${tarball}wget -q $urlpath || exit 1# 解压缩发布包tar zxvf ${tarball}# 解压缩之后,可以看到 n9e.sql 是建表语句,导入数据库mysql -uroot -p1234 < n9e.sql# 启动 n9e,先使用 nohup 简单测试,如果需要 systemd 托管,请自行准备 service 文件nohup ./n9e &> n9e.log &# 检查 n9e.log 是否有异常日志,检查端口是否在监听,正常应该监听在 17000ss -tlnp|grep 17000
至此,安装部分就结束了,接下来就是上手体验了。
三、快速上手
3.1 配置数据源
夜莺不生产日志,只是日志的“监工”。所以安装完第一件事就是配置日志数据,用法类似 Grafana 可直接接入数据源,菜单位置:「系统配置」-「数据源」,目前支持:prometheus、victoriametrics、thanos、m3、elasticsearch、loki 等数据源。

完成数据源接入之后,就可以十分方便地通过可视化的方式查看日志了。

夜莺默认提供了一些可视化大盘(菜单位置:「仪表盘」-「内置仪表盘」)和内置告警规则(菜单位置:「告警管理」-「内置规则」),导入自己的业务组(这是个管理概念,不同的告警规则和仪表盘可以使用不同的业务组分门别类管理 + 控制权限)就能使用啦。
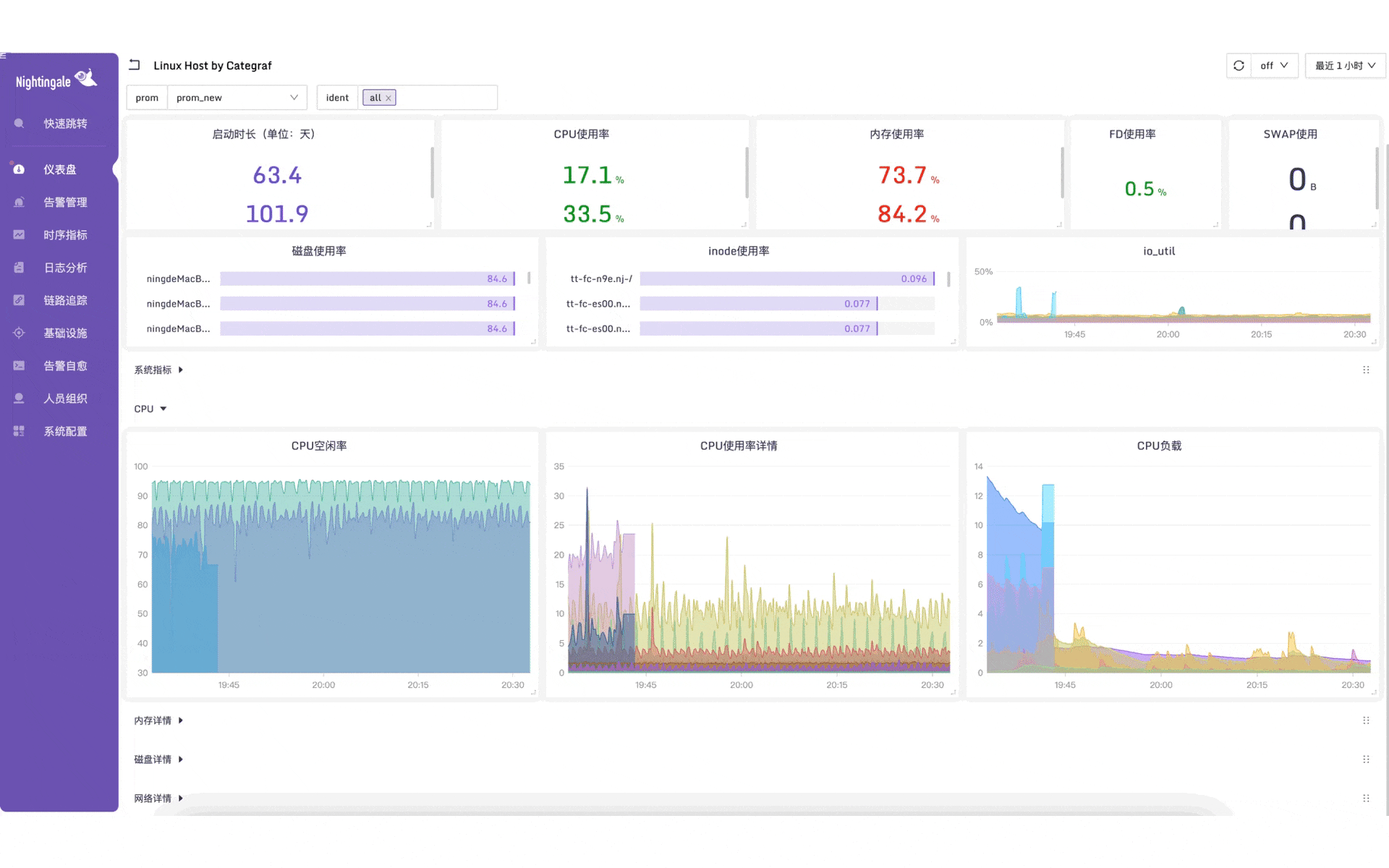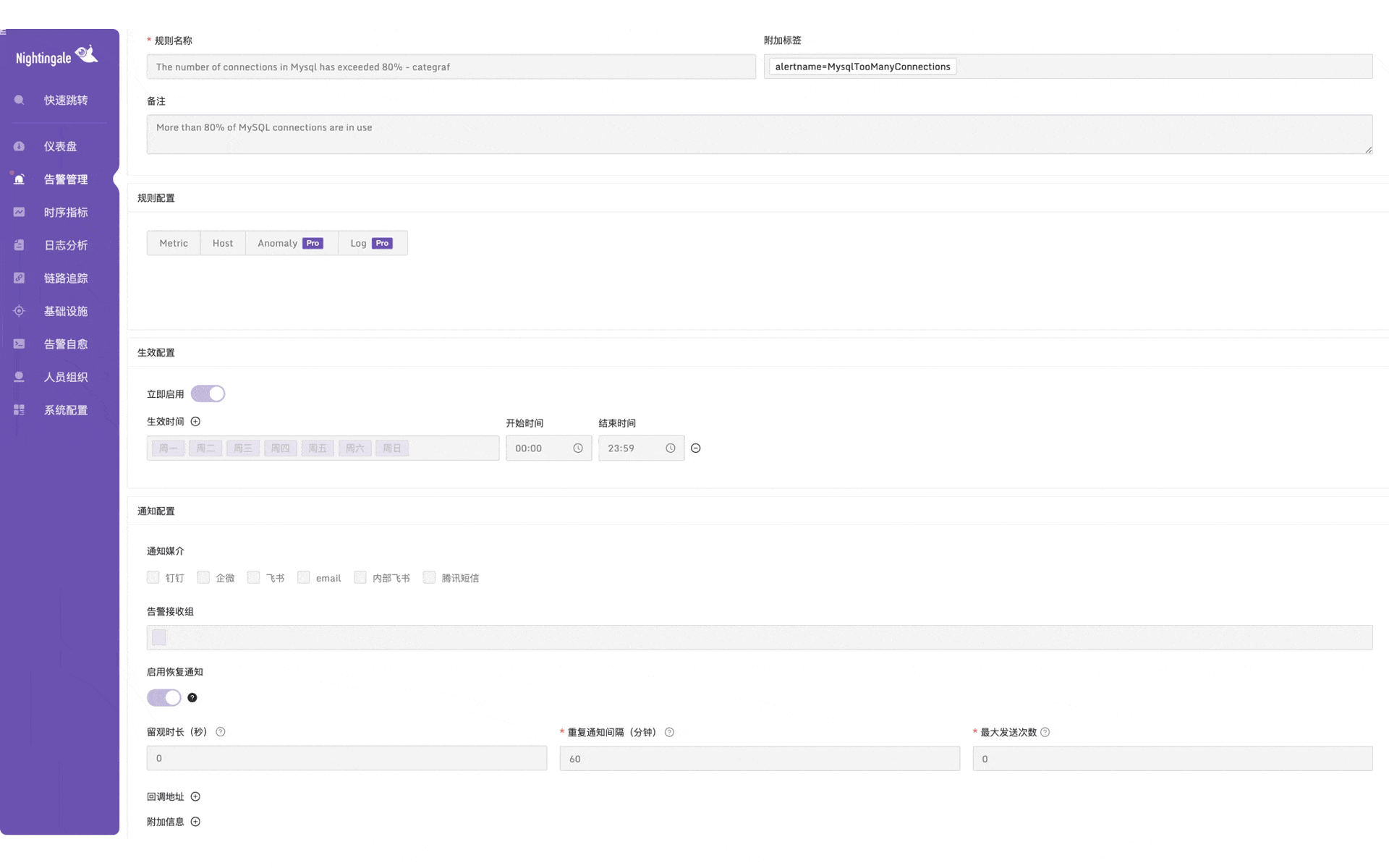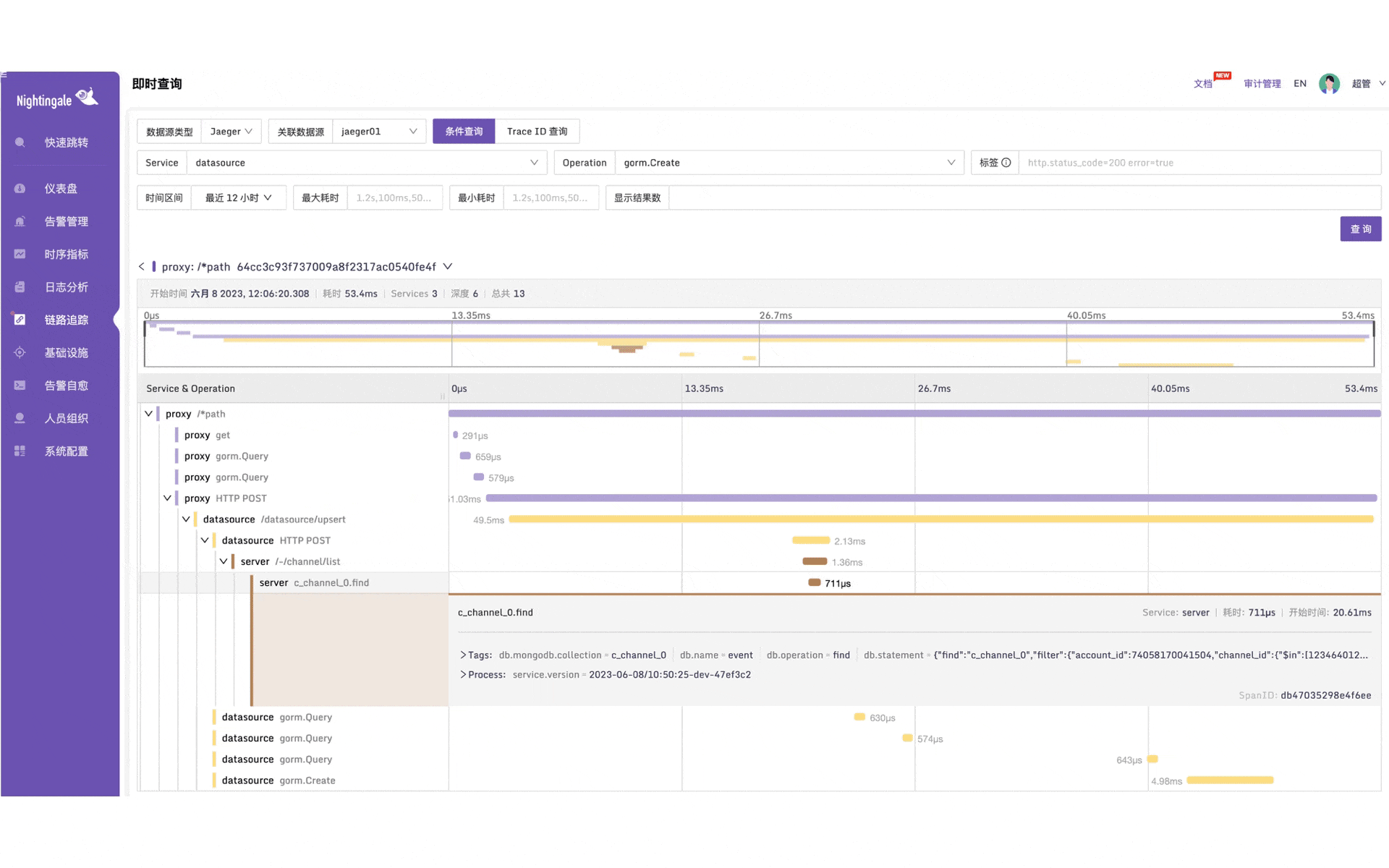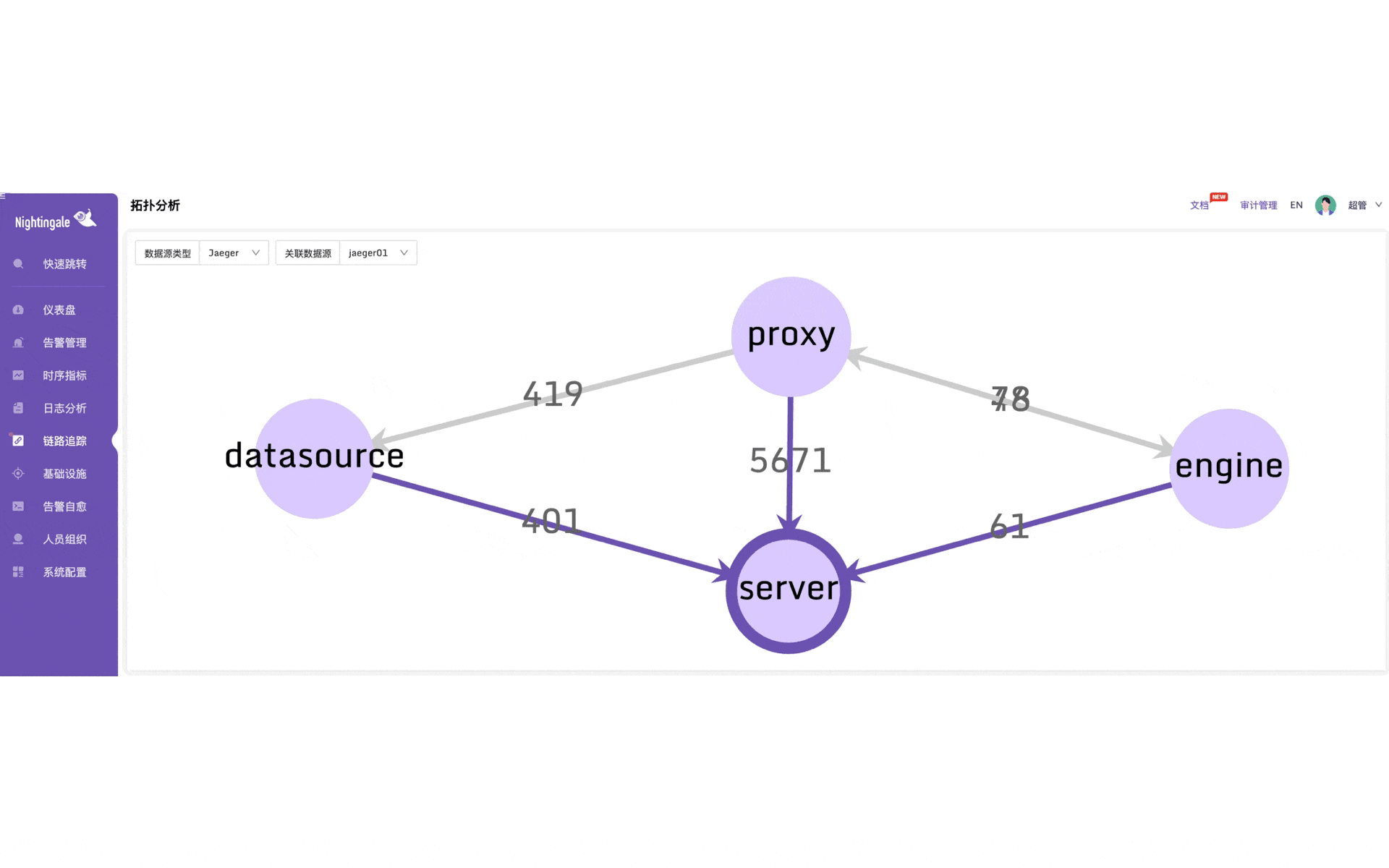
3.2 好看的仪表盘
夜莺的仪表盘展示效果美观、性能出众、功能丰富,虽然还没有 Grafana 的全面,但基本可以作为 Grafana 的国产化平替了。夜莺的仪表盘支持暗黑主题,效果如下:

前端 GitHub 地址:https://github.com/n9e/fe
3.3 采集器
如果之前没有做过监控数据收集,可以使用夜莺团队提供的采集器 categraf,这同样是一款开源的 telemetry 数据采集器,它内置了 OS、SNMP、IPMI、MySQL、Redis、MongoDB、Oracle、Kafka、ElasticSearch、cAdvisor 等多种采集插件。
GitHub:https://github.com/flashcatcloud/categraf
当然,也可以使用其他采集器,比如 telegraf、grafana-agent 等,但是 categraf 的对接最为丝滑。夜莺支持多种数据接入协议,比如 prometheus remote write、OpenTSDB、Datadog 等,接收到数据之后做统一转换,然后转发给后端时序库,具体转发给哪些时序库可以在夜莺的配置文件中配置。
3.4 告警管理
灵活的告警是优秀监控系统的标配,夜莺在这方面做得十分出色。它可以将一套规则应用于多个数据源,支持级别抑制、生效时间、告警屏蔽、告警订阅、告警自愈等规则。
- 级别抑制:高级别抑制低级别告警,比如磁盘利用率超过 95% 产生 P1 告警,超过 85% 产生 P2 告警,如果某一时刻磁盘利用率跑到 100%,就只会触发 P1 告警,P2 被抑制,避免告警打扰;
- 生效时间:可配置告警规则判定的生效时间,支持配置不同的多个日期和时段;
- 告警屏蔽:减少已知告警的干扰,比如某个机器要维护,可以提前屏蔽相关告警;
- 告警订阅:告警消息分组通知;
- 告警自愈:告警可触发预先设定好的脚本,自动解决故障;
菜单「告警管理」-「规则配置」的界面和示例如下:

四、深入了解
监控并不仅仅是可视化+告警那么简单,里面有很多道道,下面让我们“往下”走一点,深入了解下夜莺监控的架构和解决的痛点。
4.1 架构介绍
夜莺作为一款 Go 写的监控系统,不仅部署方便,而且整体设计上非常开放和灵活,可以和开源生态上其他软件组合使用,适用于已有监控系统升级或从零搭建监控平台等场景。
- 采集器:可对接 telegraf、categraf、grafana-agent、datadog-agent、以及各类 exporter;
- 存储:可对接 prometheus、thanos、m3、victoriametrics 等;
架构图如下:

从依赖上看,夜莺就只依赖 MySQL 和 Redis,它俩对于技术人员来说,都是非常熟悉的。除此之外,夜莺在部署时只需一个二进制文件 + 配置文件,将开箱即用的精神贯彻到底!
4.2 项目结构
下面简单介绍一下夜莺的项目结构,即核心功能模块介绍,方便想要深入了解夜莺的同学快速进入源码。
? # 夜莺的目录结构介绍.├── ...├── alert 告警引擎相关逻辑,对 Prometheus、Loki、TDEngine 等数据源做异常数据判断并产生告警事件。├── center Web 后端的逻辑。├── cli 命令行工具,用于 v5 版本升级 v6 版本时的数据迁移。├── cmd 入口包,所有的二进制的 main 函数入口都在这里。├── conf 配置文件在内存里映射的数据结构。├── docker 容器相关的文件,包括 Dockerfile 和 docker-compose 等,数据库的建表 SQL 也在这里。├── etc 配置文件,重点关注 config.toml,如果使用了边缘机房的部署方案,还需要关注 edge.toml。├── integrations 集成目录,包含比如 MySQL、Redis、Elasticsearch 等各个监控目标的内置仪表盘、告警规则等。├── models 数据库操作相关的代码。├── pkg 通用 lib 库。├── prom Prometheus 相关的代码,包括 remote write 写数据以及查询接口的封装。├── tdengine 查询 TDEngine(时序数据库)相关的代码。├── storage MySQL 和 Redis 的初始化连接相关的代码。└── pushgw Pushgateway 相关的代码,用于接收 remote write 数据、opentsdb 格式的数据、datadog 格式的数据、open-falcon 格式的数据,然后统一做格式转换写入后端存储。
4.3 多机房场景
你是否遇到过需要监控多机房的场景?
目前,大多数公司都有很多机房,它们分布在不同的区域,这让监控变得不再简单。因为如果机房之间网络链路很好,那么只需要部署一套监控系统就搞定了。但如果机房之间的网络不太好,无法做到监控数据实时、可靠的上传,但是告警规则又想在一个中心管理。
这个时候就需要高级部署方案,夜莺就提供了现成的边缘机房部署方案,可以方便地解决上面的问题。架构图如下:

通过夜莺提供的高级部署方案,即在网络不好的机房(边缘)部署(下沉)时序数据库和告警引擎(n9e-edge),从而保证数据不丢失和告警规则的同步,轻松构建统一的监控中心,实现多机房监控只需管理一套告警规则和可视化平台。
真·企业级监控和告警一体化解决方案!
五、最后
开源的监控系统,目前用的比较广泛的是 Zabbix 和 Prometheus,但它们或多或少都有一些不擅长的场景。
Zabbix 擅长设备监控,对各类操作系统、网络设备有较好的兼容适配,但是不擅长微服务和云原生环境的监控。
- 不擅长动态变化对象的监控:Zabbix 是资产管理式,在云原生环境下,资产是动态变化的,比如 Pod、Service、Deployment 等。
- 不擅长微服务的监控:在微服务和云原生环境下,监控指标爆炸性增长,而且指标有不同的维度描述,Zabbix 使用关系型数据库存储时序数据,不擅长处理这种大规模的多维度的指标数据。
Prometheus 擅长微服务和云原生环境的监控,基本已经成为 Kubernetes 的标配,在云原生环境下非常流行,但它也有缺点。
- 设计上偏工具化,使用配置文件来管理规则,缺少权限化管理的 WebUI。
- 使用 Prometheus 的公司通常会不止一套,比如每个 Kubernetes 一套 Prometheus,多个 Prometheus 可能有很多相同的规则,管理起来比较重复。
- 其他一些小点:告警引擎是单点,告警事件没有持久化;告警规则缺乏一些更为灵活的配置,比如生效时间;
夜莺作为一款开源的云原生监控系统,在云原生方面有着先天优势,而且使用国外的开源监控项目,最担心的就是没有技术支持,夜莺作为“100% 国产”开源项目,在技术支持上分为社区支持和商业支持(响应更及时)两种,服务的企业用户已有上千家,比如移动、联通、电信、米哈游、莉莉丝、方正证券、国泰君安、海底捞、海康、搜狐、新浪等,分布在各行各业。

最后,还是那句话:?开源不易如果觉得夜莺监控不错的话,就请给个 Star 支持一下,试用反馈遇到的问题,也是对开源的一种支持!
GitHub:https://github.com/ccfos/nightingale
官网:https://flashcat.cloud/
没有能搞定一切的银弹,或许这也是技术一直在更新迭代的动力之一吧! 所以不要停下学习的脚步??
