大家好,我是风筝
轻解网络系列又来了,今天咱们说说 IP 协议,这可是网络协议中最最核心的一个协议了,还记得我们刚刚知道什么是IP地址、怎么给电脑修改 IP 的时候吗?今天我们就来探究一下 IP 协议。
IP协议是TCP\IP协议簇中最核心的协议,大部分的上层(传输层、应用层)应用都直接或间接的使用IP协议传输,TCP协议、UDP协议都会使用 IP 协议。

这张数据在 TCP\IP 协议模型中的加工流程一定要记到脑子中,这样当我们思考网络的问题时,可以有一个大局观。
IP 协议是无连接的,不可靠的网络层协议,它只负责数据的传输,但是并不能保证数据一定能到达,要想保证数据可靠,需要上层应用处理,例如 TCP协议利用IP协议传输数据,但是丢包、超时等情况还是要靠 TCP 自己解决。
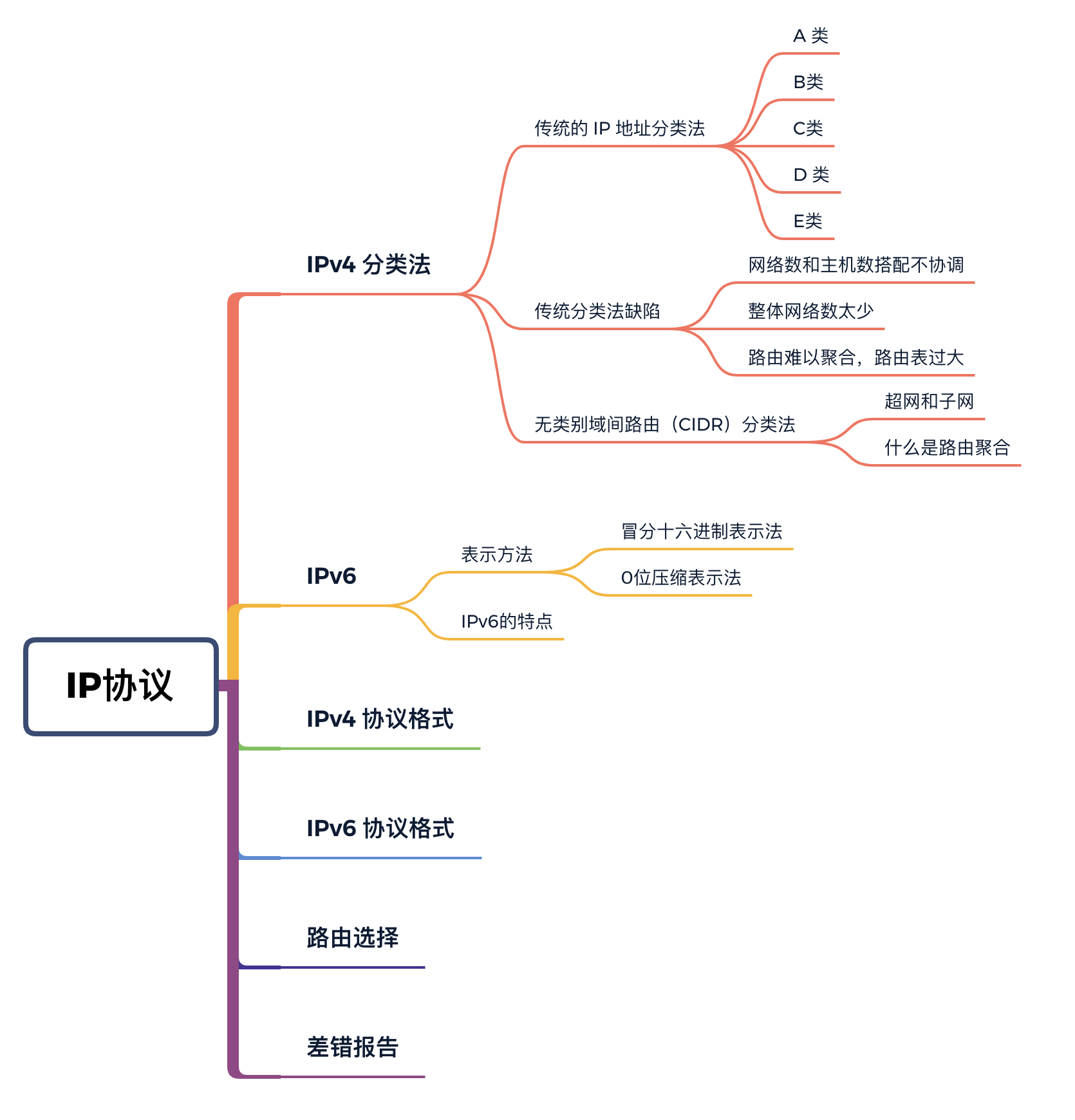
IPv4 分类法
IP 在直观上是有一个分类的,尤其是IPv4。
传统的 IP 地址分类法
在互联网诞生之初,IP 地址就有一套标准的分类方法,因为当时互联网上的设备还很少,需要用到 IP 的企业和机构也没有那么多。谁知道后来互联网发展的如此迅猛,导致这种分类方式用起来不太合理。
这种分类方式是将 IP 地址分成 A、B、C、D、E 五类,每一类都有固定的前缀和应用场景。
一个 IP 地址占用 32 bit ,用点分十进制表示,例如 192.168.0.188,一个点号分隔一个 8 bit。
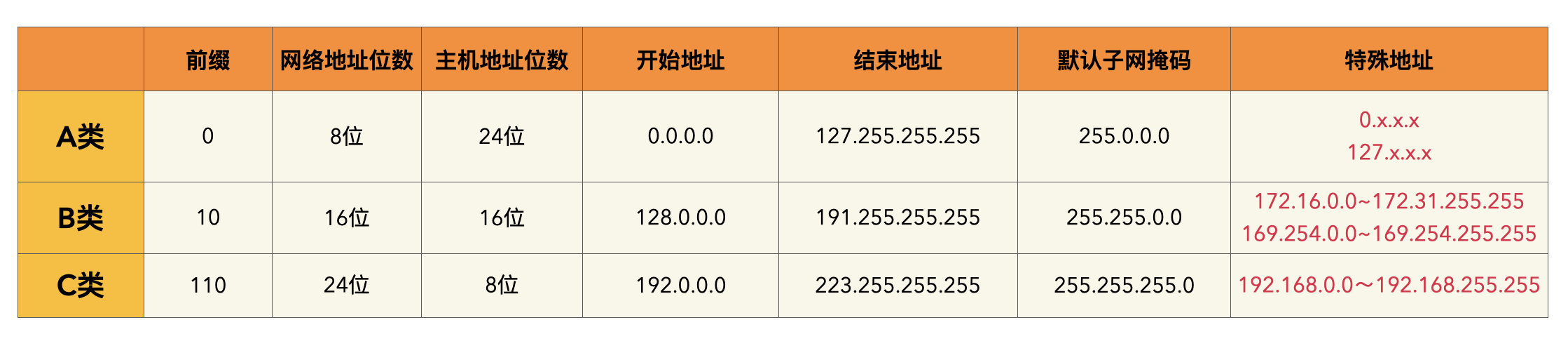
- IP 地址可分为 A、B、C、D、E 五类,D类是广播地址,E类是保留地址(未启用),所以重点关注 A、B、C类;
- A、B、C 类地址分为网络地址和主机地址,网络地址表示一个网络,主机地址分给具体的主机;
- 主机地址全为 0 和全为 1 的IP 有特殊用途,主机地址全为 0 ,表示网络号,代表这个网络本身;主机地址全为1,表示广播地址,代表这个网络中的所有主机;
- 每个类别中(除了 D、E类),都有一些地址有特殊的用户,留作私有地址或者回环地址,例如192.168、127.0.0.1;
- 子网掩码全为1的位数就是网络地址的位数;
A 类
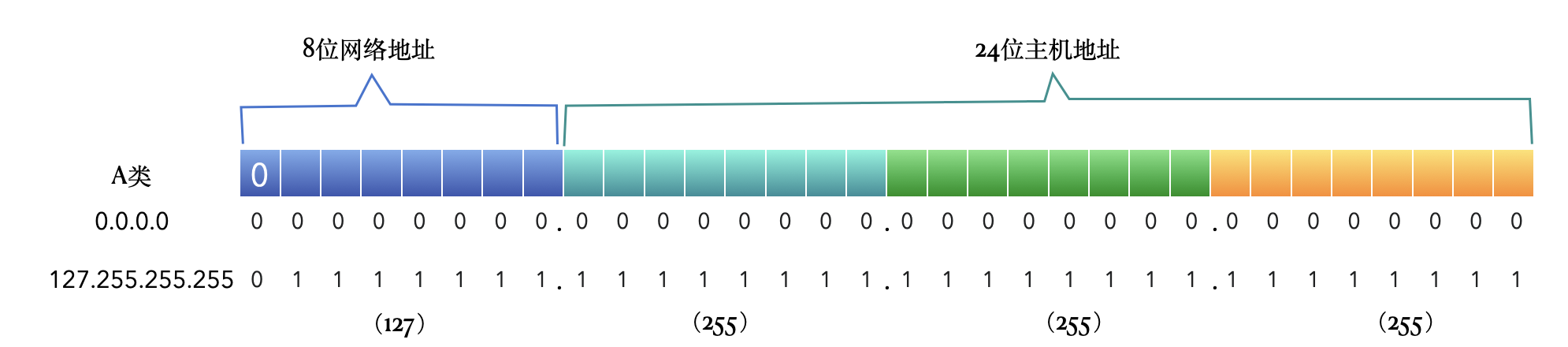
A 类地址前 8 位为网络地址,后24位为主机地址。
网络地址中第一位固定为0,有从0~127共128个网络,每个网络可容纳$2^{24}-2$ =16,777,214台主机。但其实可用的 IP 地址从 [1.0.0.0]~[126.255.255.255]。
特殊网络地址:
但其中网络地址全0和全1的为特殊地址,不能使用,所以 A 类地址可用的网络数其实是 126个。
127.0.0.1,这个地址我们都非常熟悉,一般我们说这个是本地地址(localhost),其实这个地址准确的名称叫做「回环地址」,
可以理解为一个虚拟网卡,这个网卡只接收来自本机的数据包。
0.0.0.0,这个地址其实才代表本机,假设一台主机上有两个网卡,一个服务监听了 0.0.0.0 这个IP ,则发给这两个网卡的数据都会被监听到。
还有网络地址 10 开头的地址用作内网地址,从 10.0.0.0~10.255.255.255。好多公司的内网 IP 都是10网段的。
特殊主机地址:
每一个网络,主机地址全 0 和 全 1 的都是保留地址,所以每一个网络的主机数都是$2^n-2$ ,n 是主机地址的位数。
B类
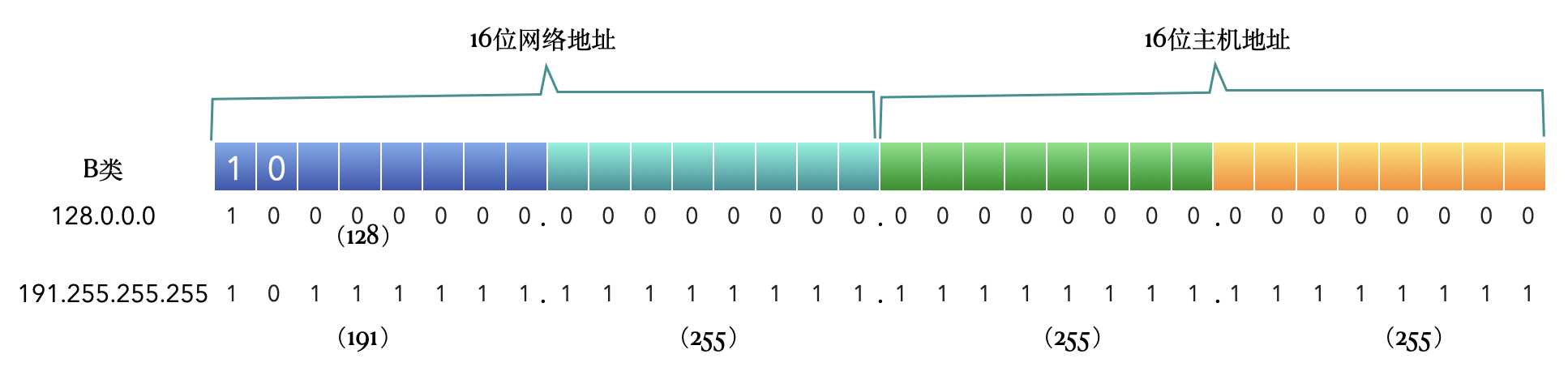
16位网络地址,16位主机地址。网络地址中前两位固定为 10,有$2^{14}$ =16384个网络,每个网络可容纳 $2^{16}-2$=65534台主机。
但其实可用的 IP 地址从128.0.0.0到191.255.255.250。
特殊网络地址:
172.16.0.0~172.31.255.255是私有地址。
10101100.0001000.00000000.00000000 ~ 10101100.00011111.11111111.11111111
169.254.0.0到169.254.255.255是保留地址。
10101001.11111110.00000000.00000000 ~ 10101001.11111110.11111111.11111111
特殊主机地址:
每一个网络,主机地址全 0 和 全 1 的都是保留地址,所以每一个网络的主机数都是 $2^n-2$ ,n 是主机号的位数。
C类
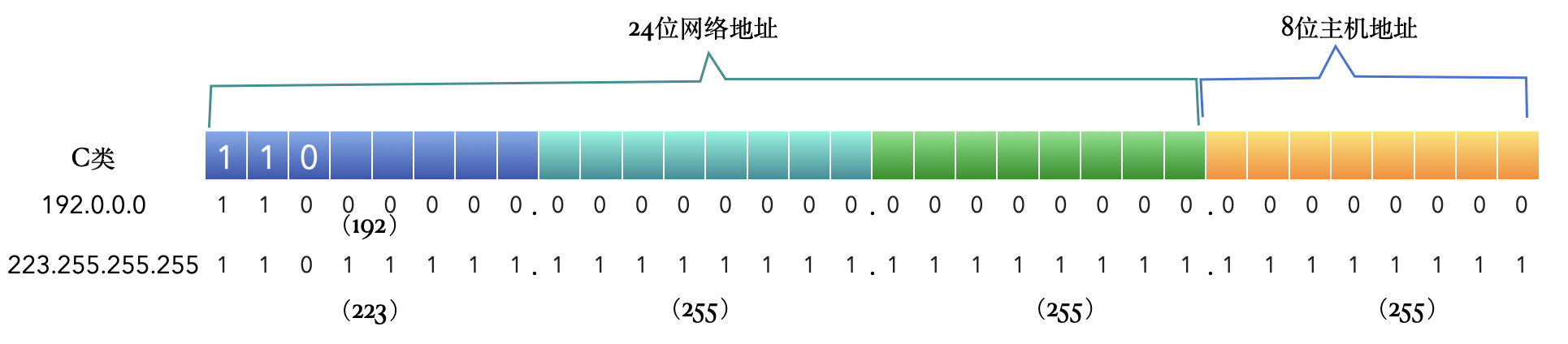
24位网络地址,8位主机地址。网络地址中前三位固定为110,有 $2^{21}$ 个网络,每个网络可容纳 $2^{8}-2$ =254台主机。
但其实可用的 IP 地址从192.0.0.0~223.255.255.255。
特殊网络地址:
192.168.0.0~192.168.255.255 留作私有地址使用。
D 类
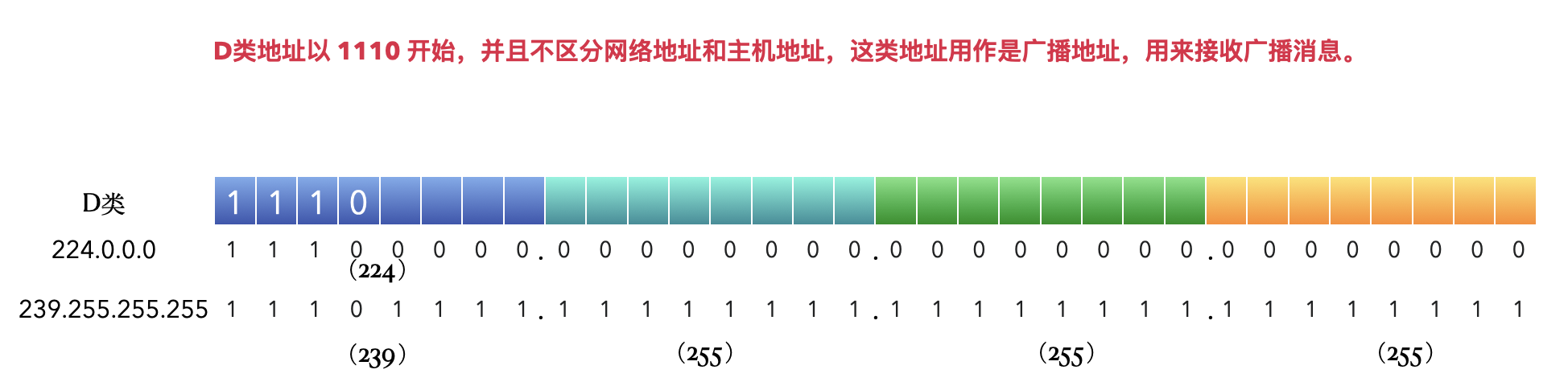
D类地址以 1110 开始,并且不区分网络地址和主机地址,这类地址用作是广播地址,用来接收广播消息
E类

E类地址以1111开始,保留地址,还未启用。
传统分类法缺陷

网络数和主机数搭配不协调
A类、B类可用网络数很少,只有1万多个,但是每个网络的主机数又太多了,
现实中没有哪个机构或企业的主机数会有那么多,所以如果一个企业得到一个B类地址,其实只能用到很少的主机地址,剩下的就浪费了。
整体网络数太少
A、B、C类的网络数加起来只有200多万个,但是全世界有那么多机构、企业,每个企业都申请一个网络地址,显然是不够用的。
路由难以聚合,路由表过大
虽然200多万的网络数据量在全世界范围内不算多,但是对于一个路由器的路由表来说就太多了。假设一个地区有十几万个 C类地址,那路由器想要路由这些地址,就要在路由表中记录这么多的路由表项,显然是不太合理的。
无类别域间路由(CIDR)分类法
正是因为传统的A、B、C、D、E类分法的一些缺陷,CIDR 便应运而生。
CIDR 仍然是用点分十进制的方式表示,IP v4 中仍然是 32 位,每8位一组,共4组。只是需要在后面加一个数字后缀,表示这个地址的网络地址是多少位。
传统的分类方法是以 8 位为最小单元,网络地址只能是8位、16位、24位,而在 CIDR 中用子网掩码区分网络地址和主机地址,连续为1的位数就是网络地址位数,用二进制可以清楚的看出来。
例如子网掩码是 11111111.00000000.00000000.00000000,前面8位连续都是1,表示8位的网络地址,子网掩码就是 255.0.0.0。
再比如子网掩码是 11111111.11100000.00000000.00000000,前面11位连续都是1,表示11位的网络地址,子网掩码就是 255.224.0.0。这与传统的 IP 地址分类法就不一样了。
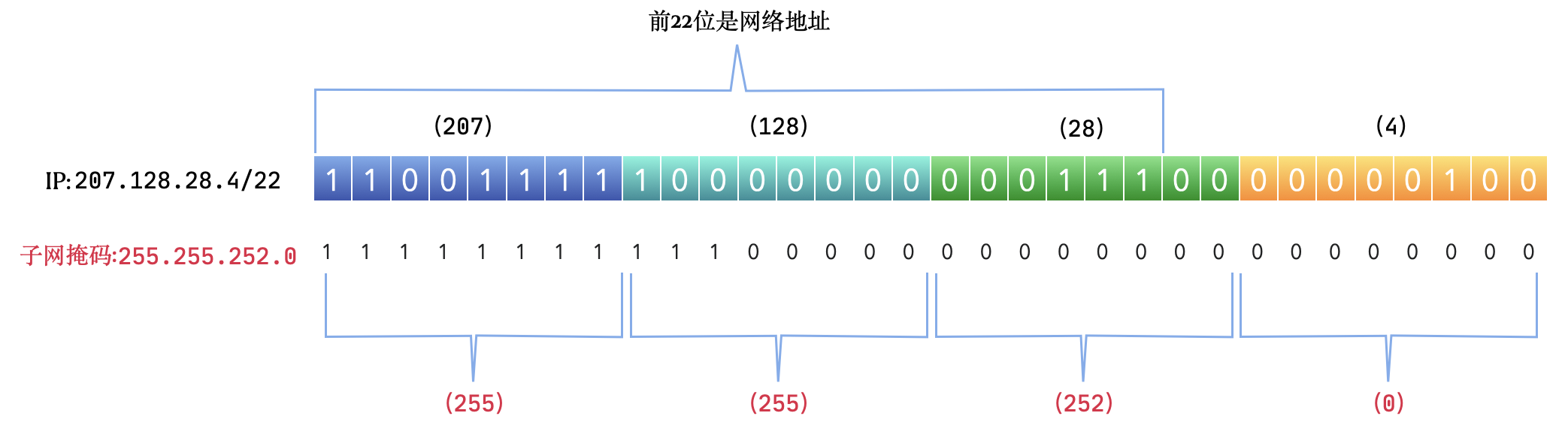
看下面两个 CIDR IP 地址,一个 11位网络地址的 IP ,一个 22 位网络地址的 IP。
例如 209.34.21.7/11,表示前11位代表网络地址,后面的21位都是主机地址。

207.128.28.4/22,表示前22位是网络地址,后面10位是主机地址。
超网和子网
IP 地址的申请有专门的管理机构控制,互联网地址顶级指派机构会负责分派超大地址块,地址块就是一个IP下包换的 IP 地址集合。 这些超大地址块会分配给大型网络提供商,大型的网络提供商又可以再分派小一些的地址块,这些小的地址块会分配给中型、小型的网络服务提供商,最后一些企业或机构再跟这些中小型的网络服务提供商申请供内部使用、有对外功能的 IP 地址。
这些分配给大型网络提供商的超大的地址块就可以被称为超网,下面分派出去的地址块可以被称为子网。当然这个超网和子网的概念是相对的,对于一个企业而言,分给它 IP 的网络服务提供商所拥有的网络就是超网。
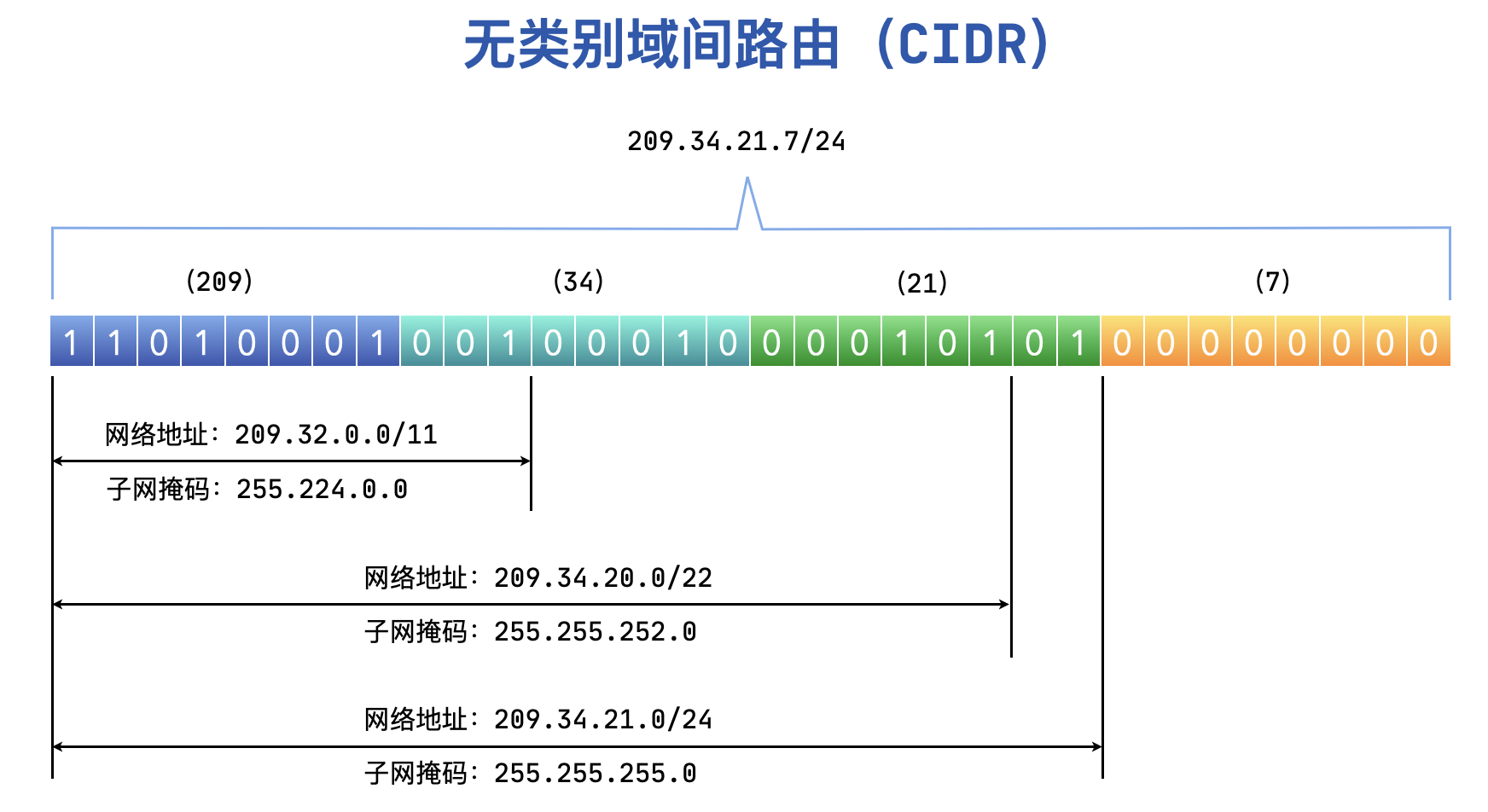
上图这个例子中,假设 209.32.0.0/11这个11位前缀的网络被分给了一个大型网络服务提供商 A,那它可分配的地址数高达 200多万个,可想而知,没有任何一家企业或机构需要这么多个 IP 地址吧。
B 是比较大的企业,财大气粗,它去找A申请,于是 A 将 209.34.20.0/22这个前缀长度为22位的地址块分给了 B 。B 的旗下还有分公司,于是它又将 209.34.21.0/24这个地址块分给了其中的一个子公司。于是这个子公司就拥有了200多个 IP 地址,比如 209.34.21.1/24。
什么是路由聚合
前面在说传统分类方式的时候,提到了一个缺点,就是路由难以聚合,可能会导致路由表过大,一个路由表可能要存上万、甚至更多的 C类地址记录。
CIDR 正好可以解决这个问题,这就是我们所说的路由聚合能力。那什么叫路由聚合呢。
路由聚合的意思是根据前缀进行聚合,有一些网络地址块它们虽然是不同的,但是他们的一部分前缀是相同的,这也是二进制的特性决定的。
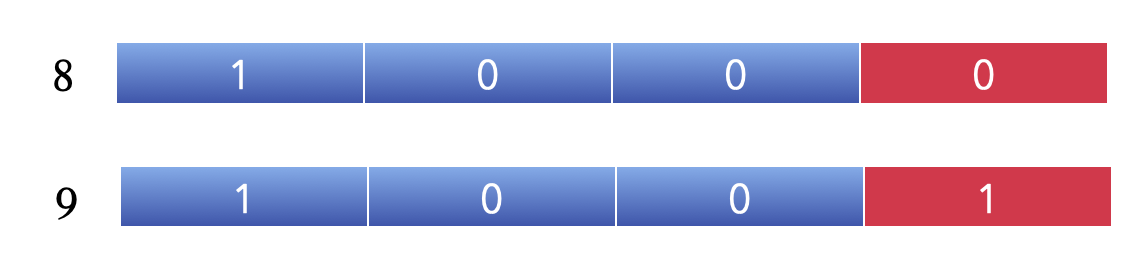
十进制的 8 和 9是完全不同的两个数对不对,但是我们把它们改为二进制的看一下,就会发现他们的前三位都是一样的。
看下面这张图中的例子,是将两个20位前缀的网络聚合为一个19位前缀的路由。
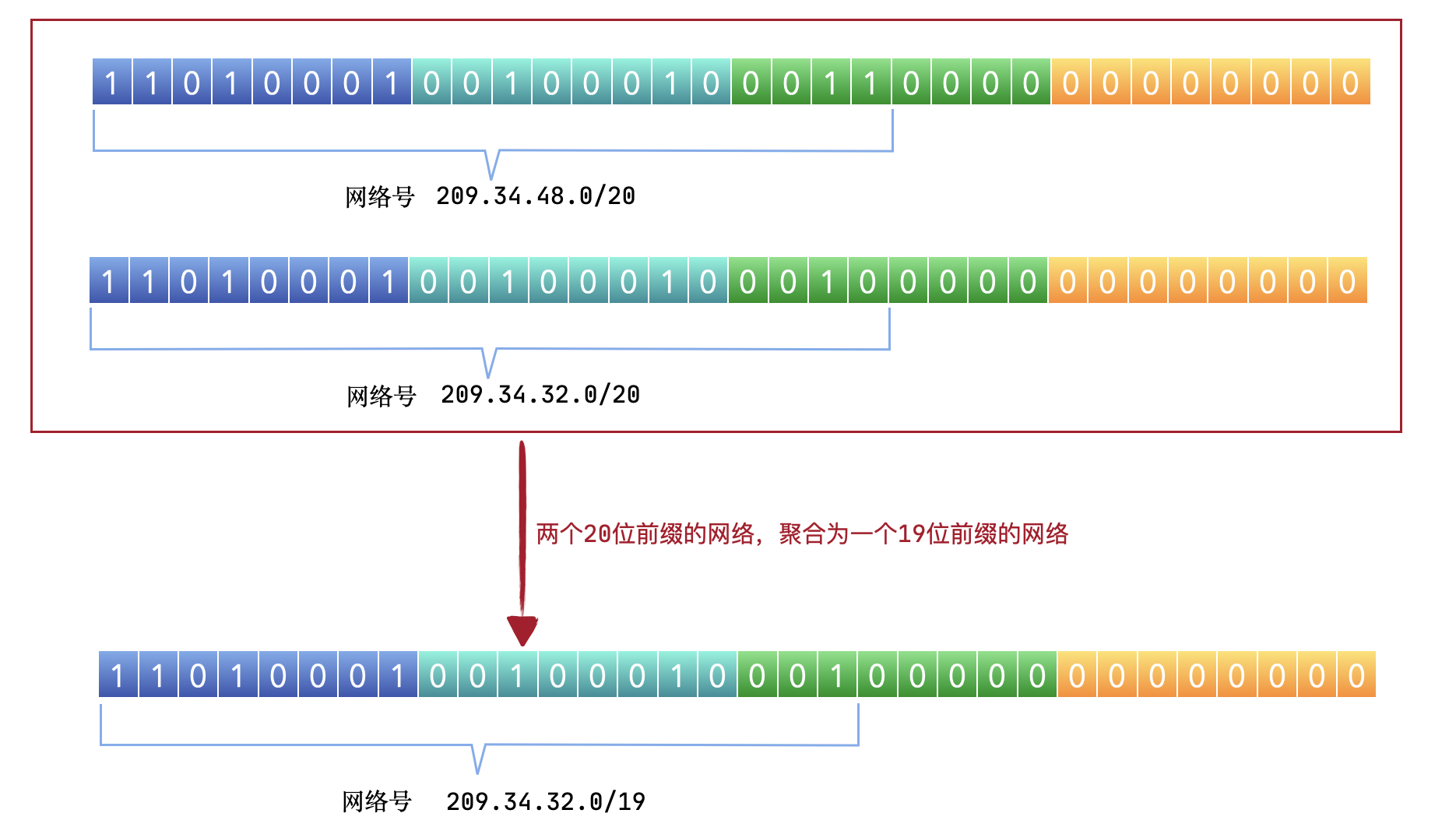
我们看到上面这两个网络 209.34.48.0/20和209.34.32.0/20,它们的前19位二进制都是完全一致的,上面说到的,相同就可以聚合,所以将前19位聚合,聚合成一个 19位前缀的网络,也就是 209.34.32.0/19。
当有访问到 209.34.48.0/20和209.34.32.0/20 这两个网络中的地址时,其实它们两个对外都是显示的 209.34.32.0/19,也就是说这两个网络都会命中 19位前缀的路由记录,也就缩小了这个路由器的记录规模,而到哪个具体的 IP,就靠子网络中的路由了。
这相当于一种分而治之的策略,保证顶层路由表不会过大,子路由表也不会过大。
IPv6
即使有了 CIDR 分类法,IPv4 的数量依然十分紧俏。目前 IPv4的地址已全部分配完毕,分到中国的大概有3亿多,而中国的终端设备这么多,大多数情况下要多个设备共用一个地址,这种情况下就要借助 NAT 技术了。
什么是 NAT
NAT 就是让多个内网主机,转成一个公网IP来连接互联网。拿平时用微信聊天来说,我们在公司的时候那么多同事共用一个热点,消息是怎么来回发送,而且每次都准确的到达终端的呢。
当发送消息的时候,消息经过 NAT 设备的转发,将发送地址变换为当前网络对外的公网地址;
当接收到消息时,消息经过 NAT 设备,根据 NAT 设备记录的信息(和端口号有关),将消息转发给对应的内网终端。
但是 NAT 会导致网络的性能变差,而且 NAT 也是有数量限制的。这就使得 IPv6 势在必行了,目前,有很大一部分互联网公司都已经支持 IPv6了。
IPv6地址长度为 128位(bit),是IPv4的4倍。其所包含的 IP 个数为 $2^{128}$个,这个数字太大了,这么说吧,按照现在的人口数,随便用,根本就用不完。
表示方法
常用的就是前面两种。
冒分十六进制表示法
用 8 组冒号分隔的16进制数分隔,例如 2408:8207:2462:bcc0:89b:16e1:771d:4bec
0位压缩表示法
在某些情况下,一个IPv6地址中间可能包含很长的一段0,可以把连续的一段0压缩为“::”。但为保证地址解析的唯一性,地址中”::”只能出现一次,例如:
FF01:0:0:0:0:0:0:1101 → FF01::1101
0:0:0:0:0:0:0:1 → ::1
0:0:0:0:0:0:0:0 → ::
IPv6的特点
-
IP地址依然适应互联网分层构造。分配与其地址结构相适应的IP地址,尽可能避免路由表膨胀。
-
包首部长度采用固定的值 (40 字节),不再采用首部检验码。简化首部结构,减轻路由器负荷。路由器不再做分片处理(通过路径 MTU 发现只由发送端主机进行分片处理),提升了性能。
-
支持即插即用功能,即使没有DHCP 服务器也可以实现自动分配IP 地址。
-
采用认证与加密功能,应对伪造 IP 地址的网络安全功能以及防止线路窃听的功能 (IPsec)。
IPv4 协议格式
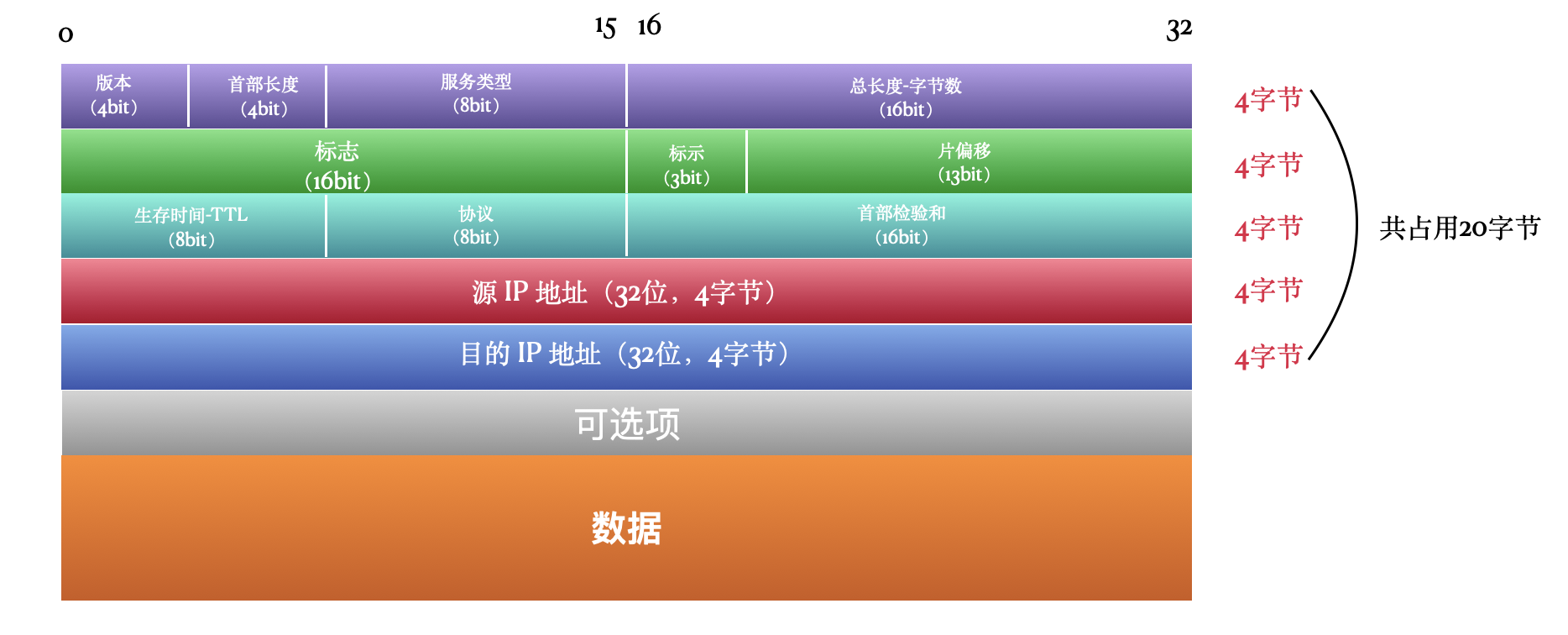
版本
版本字段占用 4 bit,用来标示当前使用的 IP 协议版本,只有 IPv4(0100) 和 IPv6(0110) 两个版本区分。
首部长度
首部长度表示占32bit的数目,也就是有多少个4字节(32bit/8=4字节),比如首部长度是5,就表示有5个4字节,也就是20个字节。
而用来表示首部长度的字段是4bit,这样一来它可表示的最大长度就是二进制的「1111」,也就是2^4-1=15,也就是最大可以是 15个4字节,也就是15*4=60个字节,也就是说首部的最大长度是60个字节,而通过图可以看出来固定的部分占20字节,那可选项部分的最大长度就是40字节。
服务类型

服务类型,英文全称 Type of Service。用来标示是一个什么类型的应用正在使用IP协议。
前面 3 个bit 用来标示优先级,但现在已经被忽略了。接着 4 个bit 用来标示子类型,每一个bit分别代表最小延迟、最大吞吐量、最高可靠性、最小费用。例如 Telnet 应用要求最小延迟,所以这4个bit分别是 「1000」。
最后一个bit是保留位,但必须是0。
但是现在很少有应用支持 TOS,所以了解一下就可以了。这属于理想很丰满,现实很骨感的一个体现。标准是标准,但是实现上会有一定差异。
总长度字段
IP 报文除了首部还要携带数据,总长度字段指整个 IP 报文的长度,单位是字节。总长度字段占2个字节,16bit,这样算下来,总共可以表示2^15-1 ,也就是65535个字节。虽然可以表示这么多字节,但是绝多数情况下都不会一次性传输这么大的数据量,会有很多因素影响每个数据报的最大值。
数据报的最大长度主要和上层应用限制和MTU限制有关系。
例如DNS服务就限制数据报最大长度为 512字节。
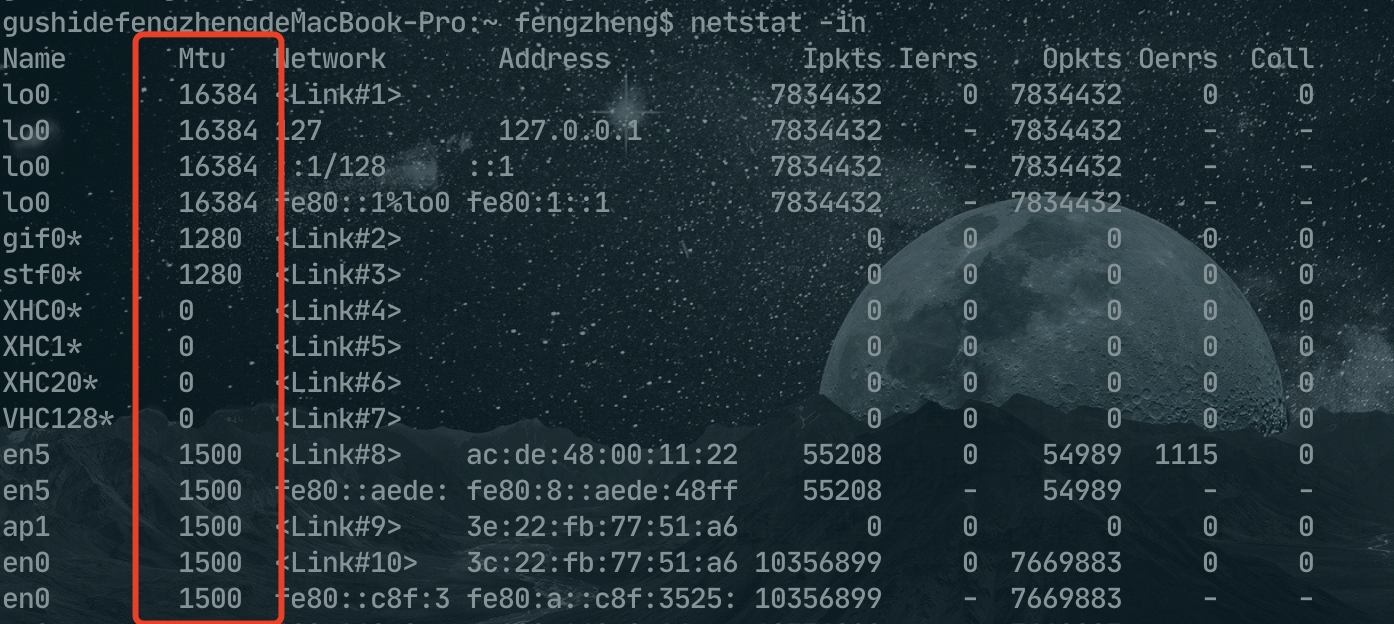
另外我们常用的以太网 MTU (最大传输单元)就是 1500字节,所以在以太网上的报文不能超过 1500字节。
可以用 netstat -in 查看本机网络接口的 MTU。
总长度-首部长度=数据长度。有一种情况,以太网要求报文的最小长度是46字节,但是 IP 数据报的总长度可能不足46字节,例如只传输很少的数据,这种情况下,以太网链路层就要将不足46字节的部分补全。这样一来,当接收方IP层接到这个报文后,就可以通过总长度字段和首部长度得出真正的数据长度,从而将后面多余的数据部分去掉。
分片标示

如果报文超过 IP 层允许的最大报文长度,就会进行 IP 分片,将原本的大报文分片成一个个小的报文,每一个小的报文都可能会从不同的路径发送到目标主机,而每一个分片报文发送到目的主机的顺序也不一定是按照原有顺序到达的。所以,在目的主机端获取到所有的报文分片后,要按照原始的顺序将一个个小的分片还原成原始的报文。
在还原的过程中就需要知道各个分片的顺序,标志、标示和片偏移字段就是为了完成这个还原的过程。
标志字段,当数据报被分片后,来自一个大报文的每个分片都会被赋予相同的值,用来表示这些分片来自同一个报文,在报文还原的时候用。
标示字段为 3 占3个bit,第一位始终是0,第二位是DF位,如果是1表示不分片,第三位是MF,如果是1,表示这个分片不是最后一个,后面还有更多的分片。
片偏移字段表示这个分片的偏移量,单位是 8 个字节,也就是 8*8=64个bit。例如第一个分片的偏移量是0,第二个分片的偏移量是1,则第二个分片相对第一个分片的偏移量是1,也就是 8 个字节。如下图所示。
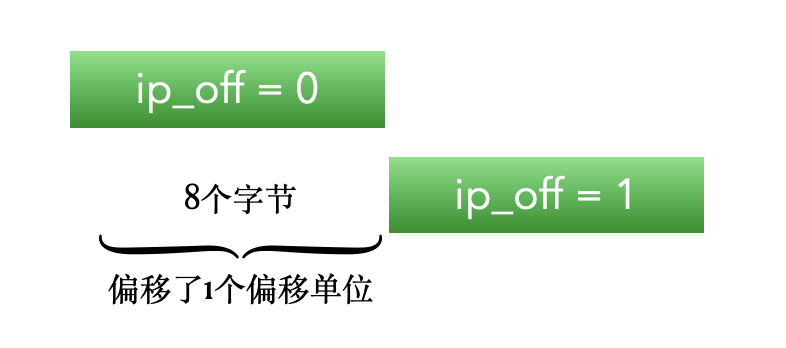
如果第二个偏移量的值是3,则相对于第一个分片的偏移量是 3*8字节=24字节。
TTL
IP数据报的生存时间,单位不是时间单位,而是跳数。在网络上,没经过一个路由器,叫做一跳,例如我们经常听到的下一跳路由,就是指一个数据包要经过的下一个路由器。
一般TTL是32或64,由初始主机设置,表示这个IP报文最多可经过32个路由或64个路由,每经过一个路由器,TTL 的值就减一,当这个值为0时,路由器就直接将这个报文丢弃。并发送 ICMP 报文给源主机,由源主机商的服务决定是重发还是怎么样。
之所以要设置一个值,是防止浪费太多网络资源,如果一个报文经过了好多路由器还没有到达目的地,很有可能就是网络有问题了,比如进入了一个循环网络,或者目的端未联网。
协议
协议字段,长度为8个bit,标识了上层所使用的协议,下面是几个比较常用的协议号。
1:ICMP,2:IGMP,6: TCP,17: UDP
首部检验和
首部检验和用来检验一份报文的正确性,当报文到达目的端后,用首部检验和规定的校验方法计算,并用计算出的结果和此报文本身携带的首部检验和字段做比较,如果结果一致,则说明报文没有问题,如果结果不一致,则直接丢弃报文。
在传输过程中 TTL 的值会一点点减小,所以在TTL减小的同时,也会动态调整首部检验和的内容,因为如果首部检验和如果不根据TTL进行调整的话,在报文达到目的端后,根据首部各字段的值进行计算,由于TTL已经减小,最终算出的检验和必定会与最开始的检验和不一致,即使是没有问题的报文也会被丢弃。
可选项
可选项可有可无,它有如下几种功能:
? 安全和处理限制(用于军事领域)
? 记录路径(让每个路由器都记下它的 IP地址)
? 时间戳(让每个路由器都记下它的 IP地址和时间)
? 宽松的源站选路(为数据报指定一系列必须经过的 IP地址)
? 严格的源站选路(与宽松的源站选路类似, 但是要求只能经过指定的这些地址, 不能经过其他的地址)。
这些选项很少被使用,并非所有的主机和路由器都支持这些选项。 选项字段一直都是以 32 bit作为界限,在必要的时候插入值为 0的填充字节。这样就保证 IP首部始终是32 bit的整数倍。但是最大长度不能超过40字节。
数据
数据就是真正要传输的内容了,当然包括上一层的头信息,例如 TCP头、UDP头。
IPv6 协议格式
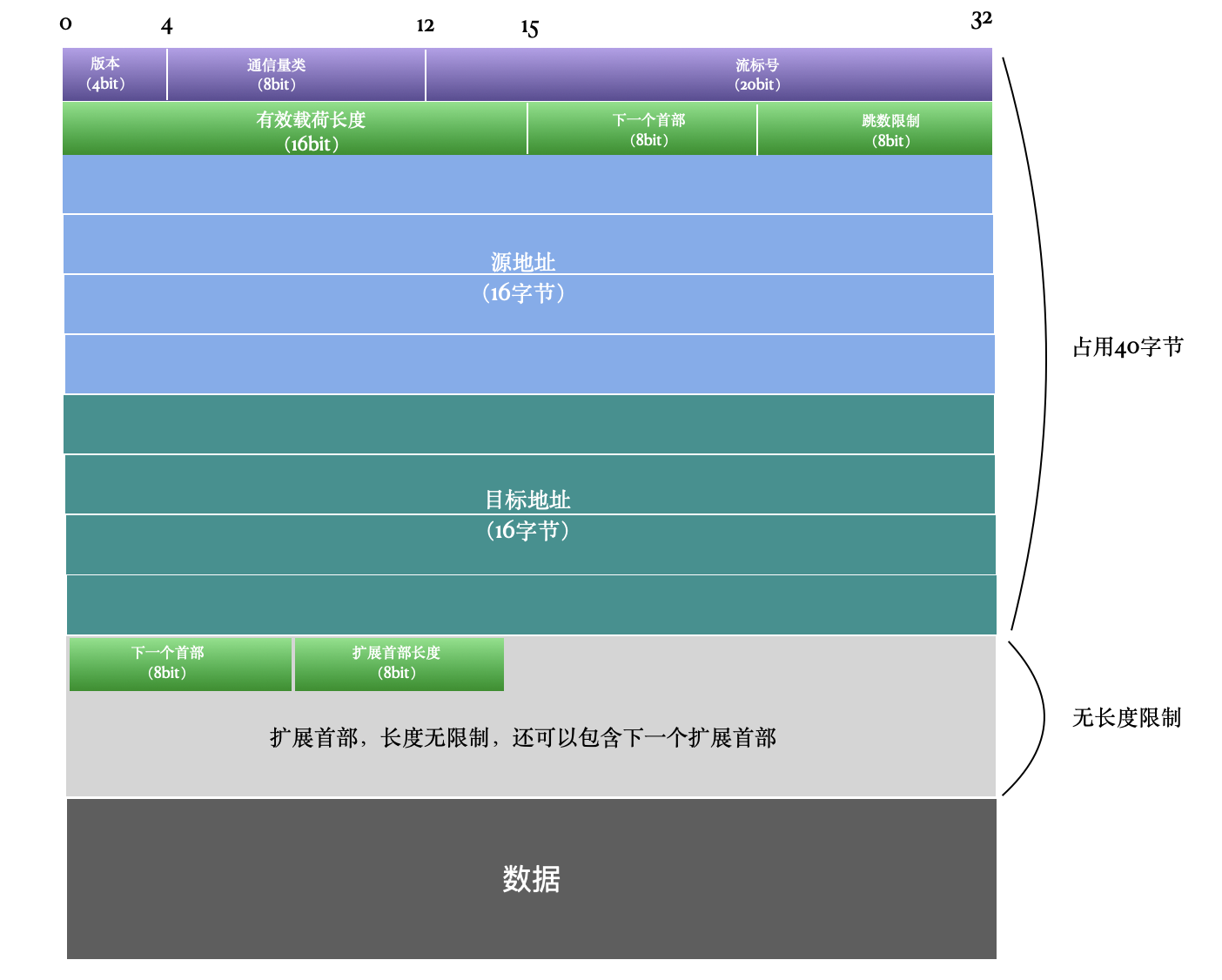
版本
版本字段占用 4 bit,用来标示当前使用的 IP 协议版本,IPv6 固定为 0110,也就是 6 。
通信量类
相当于IPv4 的 TOS (Type Of Service)字段,占用8 bit。由于 TOS 在 IPv4 中几乎都没有什么用处,未来可能会删掉这个字段。
流标号
占用20bit,准备用于服务质量(QoS)控制。使用这个字段提供怎样的服务已经成为未来研究的课题。不使用 QoS时,直接将所有位设置为 0 即可。
在进行服务质量控制时,将流标号设置为一个随机数,然后利用一种可以设置流的协议 RSVP (Resource Reservation Protocol)在路由器上进行QoS 设置。当某个包在发送途中需要 QoS时,需要附上 RSVP 预想的流标号。路由器接收到这样的 IP 包后先将流标号作为查找关键字,迅速从服务质量控制信息中查找并做相应处理。
此外,只有流标号、源地址以及目标地址三项完全一致时,才被认为是一个流(例如数据包进行了分片)。
有效载荷长度
占用 16bit,有效荷载长度是指包的数据部分的长度。IPv4的总长度是指包含首部在内的所有长度。然而IPv6中的这个有效载荷长度不包括首部,只表示数据部分的长度。
下一个首部
占用 8 bit,相当于IPv4中的协议字段。通常表示IP的上一层协议是TCP或UDP。不过在有IPv6扩展首部的情况下,该字段表示后面第一个扩展首部的协议类型。
跳数限制(Hop Limit)
占用 8 bit。与 IPv4中的TTL概念一致。为了强调“可通过路由器个数”这个概念,才将名字改为Hop Limit。数据每经过一次路由器就减1,减到0则丢弃数据。
源地址
占用128bit,16字节。表示发送端IP地址。因为 IPv6 长度就是128bit。
目标地址
占用128bit,16字节。表示接收端IP地址。
扩展首部
IPv6的首部长度是固定的,共40字节。IPv4中的可选项就没地方放了,而 IPv6 增加了扩展首部的概念,通过扩展首部来实现IPv4中的可选项。 在IPv4中可选项长度固定为40字节,但是在IPv6中没有这样的限制。也就是说,IPv6的扩展首部可以是任意长度。扩展首部当中还可以包含扩展首部协议以及下一个扩展首部字段。
数据
要传输的数据,当然也就包含上层的头信息,例如UDP头、TCP头。
路由选择
IP协议有一个特别重要的特质就是路由选择,就是决定一个 IP 数据报从哪条路走,最终能不能成功的到达目的端,全靠 IP 的路由选择功能。
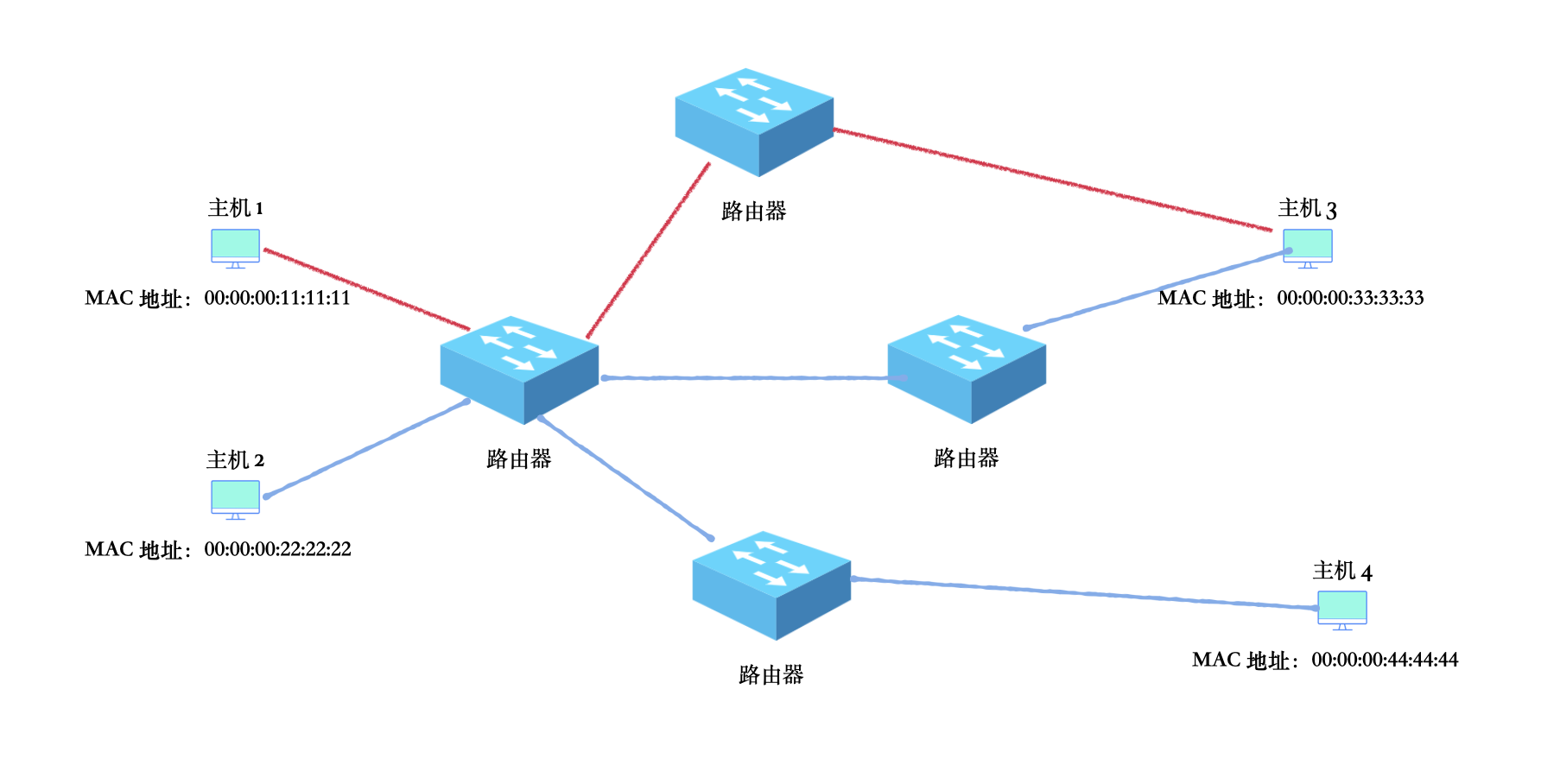
如上图所示,主机1想把数据发往主机3,中间经过两个路由器,真实环境下会更多。最终路径假设是图中红线连接的部分,每一个红线都称为一跳。
IP数据包在每次发往下一跳地址的时候都会被重新封装,封装的头信息中的目的地址就是下一跳的 IP 地址。
每一个设备是怎么得到下一跳 IP 的呢,这就要提到路由表了。
路由器(包括可转发数据的主机)中维护着一张路由表,主要存放网络、主机与下一跳的对应关系。例如下表这样:
| 目标 |
子网掩码 |
下一跳 |
网络接口 |
| 192.168.8.0 |
255.255.255.0 |
0.0.0.0 |
en0 |
| 114.21.1.0 |
255.255.255.0 |
114.21.1.100 |
en0 |
| 0.0.0.0 |
0.0.0.0 |
192.168.8.1 |
en1 |
差错报告
前面说了,IP 协议不可靠,不保证数据一定能正确到达目的端,但是它还是提供了必要的差错报告机制,用来返回给上层使用程序,让上一层知道当前传输的数据发生了什么错误。至于如何处理,就不管了。
差错报文用 ICMP 协议发送,ICMP 是互联网控制报文协议,分为主动查询报文和差错报告报文,主动查询的例如 ping命令,绝大多数都是为了表示数据传输过程中发生了错误,以此来提示发送端。
发送ICMP差错报文
例如当数据包到达一个路由器,在路由器搜索了路由表的所有记录后,仍然没有发现合适的记录,并且路由表也没有配置默认项(默认项就是在没有找到绝对匹配的记录时默认发送的配置),这时候就会发送一个 ICMP 差错报文,表示网络或主机不可达,发送给谁呢,发送给这个IP数据包的发送端。
发送ICMP重定向报文
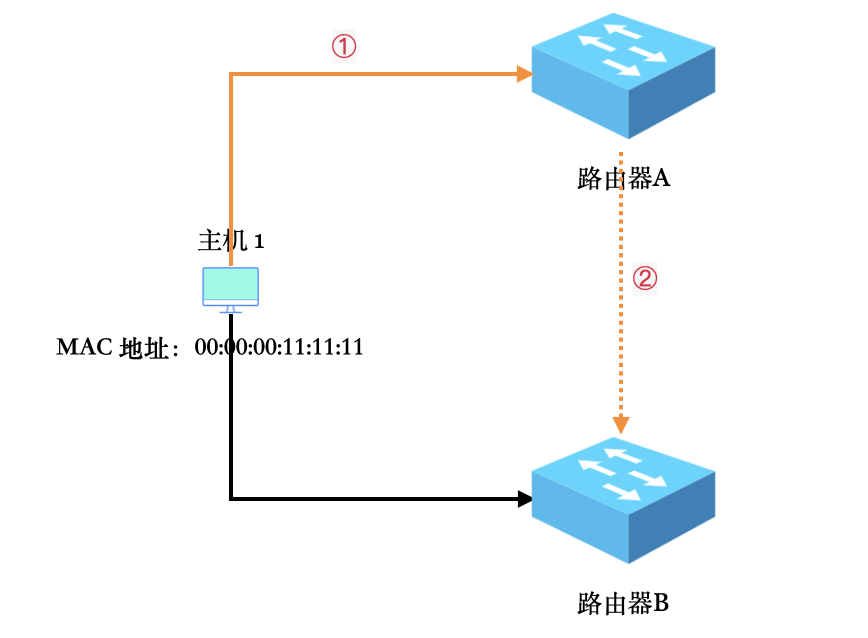
重定向报文更像是一种优化策略,如图,假设一个主机同时连接了两台路由器A和B,而路由表中只有其中一个路由器A的配置项。在某次发送数据时,主机1将数据包发给下一跳路由器A,而路由器A接收到数据包后,通过路由选择,下一跳是路由器B,就是图中红色的①②的路径,而此时路由器A发现自身、路由器B、主机1在同一局域网中,此时,路由器A便向主机1发送一个ICMP重定向报文。用来告诉主机1,“下次再有类似的包,直接发给路由器B就行了,别绕弯子了”。
如果觉得还不错的话,给个推荐吧!
公众号「古时的风筝」,Java 开发者,专注 Java 及周边生态。坚持原创干货输出,你可选择现在就关注我,或者看看历史文章再关注也不迟。长按二维码关注,跟我一起变优秀!

