1,什么是cdc
CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
2,flink的cdc
项目地址:https://github.com/ververica/flink-cdc-connectors
项目文档:https://ververica.github.io/flink-cdc-connectors/master/
3,环境准备
- mysql
- elasticsearch
- flink on yarn
说明:如果没有安装hadoop,那么可以不用yarn,直接用flink standalone环境吧。
本例使用版本如下:
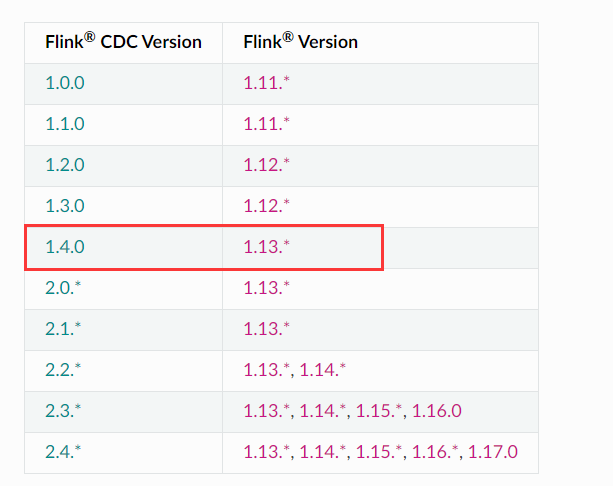
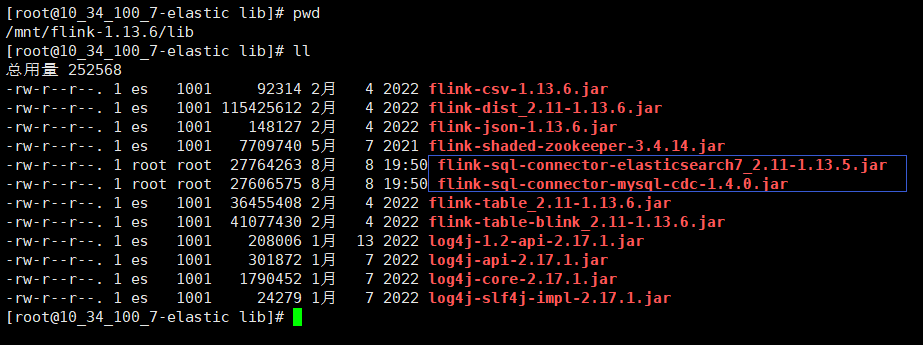
下面两个地址下载flink的依赖包,放在lib目录下面。
下载地址:
1、https://repo.maven.apache.org/maven2/com/alibaba/ververica/
flink-sql-connector-mysql-cdc-1.4.0.jar
此仓库提供的最新版本为1.4.0,如需新版本可自行编译或者去https://mvnrepository.com/下载。
2、https://repo.maven.apache.org/maven2/org/apache/flink/
flink-sql-connector-elasticsearch7_2.11-1.13.5.jar
小坑:此处使用的是es7,由于本地环境是es8导致无法创建索引,又重新安装es7测试成功。
4,启动flink
启动flink集群
启动成功的话,可以在 http://localhost:8081/ 访问到 Flink Web UI,如下所示:
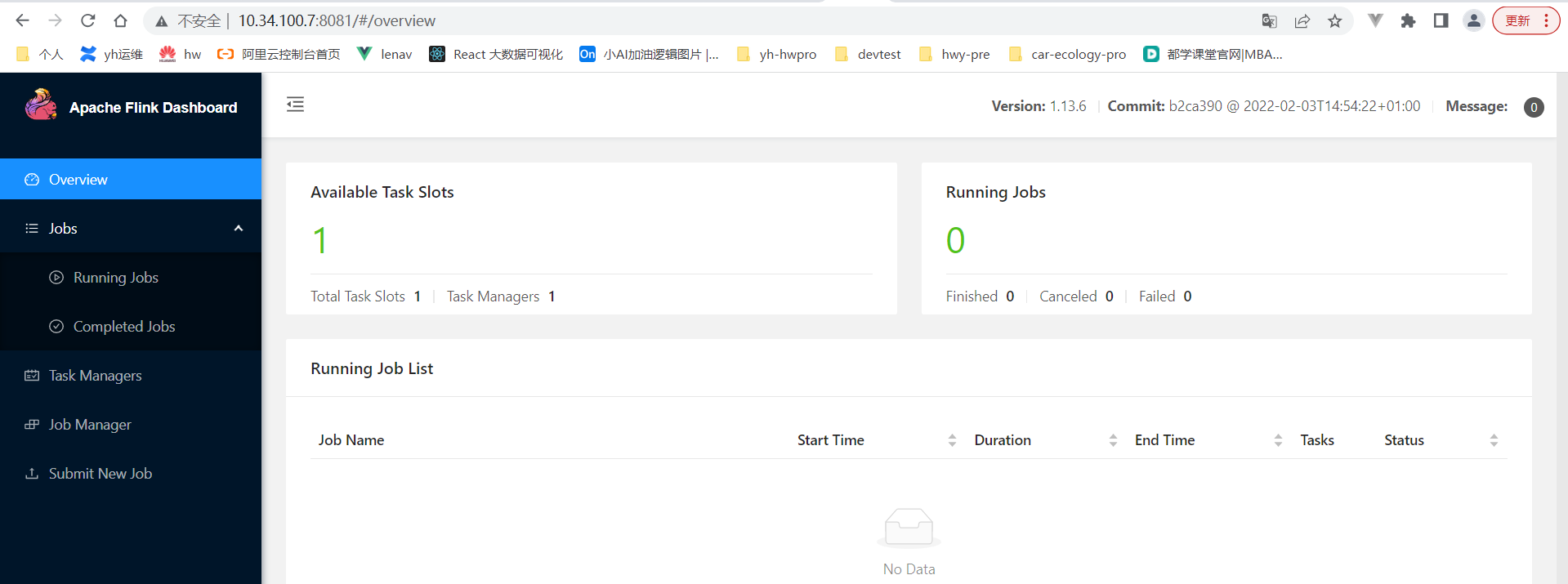
启动flink sql-client
- ./sql-client.sh
不加任何参数进入交互式界面。
./sql-client.sh -f /tmp/aa.sql
-f:就是接sql文件。即不用进行交互式查询,这里注意:aa.sql文件里的insert语句会被分开成一个个job。
如果想要在一个job里提交就要注意写法,即:
在1.15.0以前语法:
BEGIN STATEMENT SET;
-- one or more INSERT INTO statements
{ INSERT INTO|OVERWRITE <select_statement>; }+
END;
自定义job名称: set pipeline.name = totalTask;
启动成功后,可以看到如下的页面:

5,数据同步初始化
1)mysql数据库原始表
- CREATE TABLE `product_view` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `user_id` int(11) NOT NULL,
- `product_id` int(11) NOT NULL,
- `server_id` int(11) NOT NULL,
- `duration` int(11) NOT NULL,
- `times` varchar(11) NOT NULL,
- `time` datetime NOT NULL,
- PRIMARY KEY (`id`),
- KEY `time` (`time`),
- KEY `user_product` (`user_id`,`product_id`) USING BTREE,
- KEY `times` (`times`) USING BTREE
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 样本数据INSERT INTO `product_view` VALUES ('1', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');INSERT INTO `product_view` VALUES ('2', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');INSERT INTO `product_view` VALUES ('3', '1', '1', '3', '120', '120', '2020-04-24 13:14:00');INSERT INTO `product_view` VALUES ('4', '1', '1', '2', '120', '120', '2020-04-24 13:14:00');INSERT INTO `product_view` VALUES ('5', '8', '1', '1', '120', '120', '2020-05-14 13:14:00');INSERT INTO `product_view` VALUES ('6', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');INSERT INTO `product_view` VALUES ('7', '8', '1', '3', '120', '120', '2020-04-24 13:14:00');INSERT INTO `product_view` VALUES ('8', '8', '1', '3', '120', '120', '2020-04-23 13:14:00');INSERT INTO `product_view` VALUES ('9', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
2)flink 创建source数据库关联表
- CREATE TABLE product_view_source (
- `id` int,
- `user_id` int,
- `product_id` int,
- `server_id` int,
- `duration` int,
- `times` string,
- `time` timestamp,
- PRIMARY KEY (`id`) NOT ENFORCED
- ) WITH (
- 'connector' = 'mysql-cdc',
- 'hostname' = '10.34.100.209',
- 'port' = '3306',
- 'username' = 'root',
- 'password' = '123',
- 'database-name' = 'flinkcdc_test',
- 'table-name' = 'product_view',
'server-id' = '5401' - );
这样,我们在flink-sql client操作这个表相当于操作mysql里面的对应表。
3)flink 创建sink,数据库关联表elasticsearch
- CREATE TABLE product_view_sink(
- `id` int,
- `user_id` int,
- `product_id` int,
- `server_id` int,
- `duration` int,
- `times` string,
- `time` timestamp,
- PRIMARY KEY (`id`) NOT ENFORCED
- ) WITH (
- 'connector' = 'elasticsearch-7',
- 'hosts' = 'http://10.34.100.156:9200',
- 'index' = 'product_view_index'
- );
这样,es里的product_view_index这个索引在数据同步时会被自动创建,如果想指定一些属性,可以提前手动创建好索引。往product_view_sink里面插入数据,可以发现es中已经有数据了。
查看flink创建的表
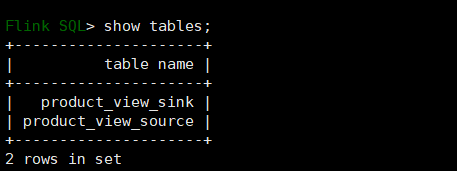
查看flink表数据
- select * from product_view_source;
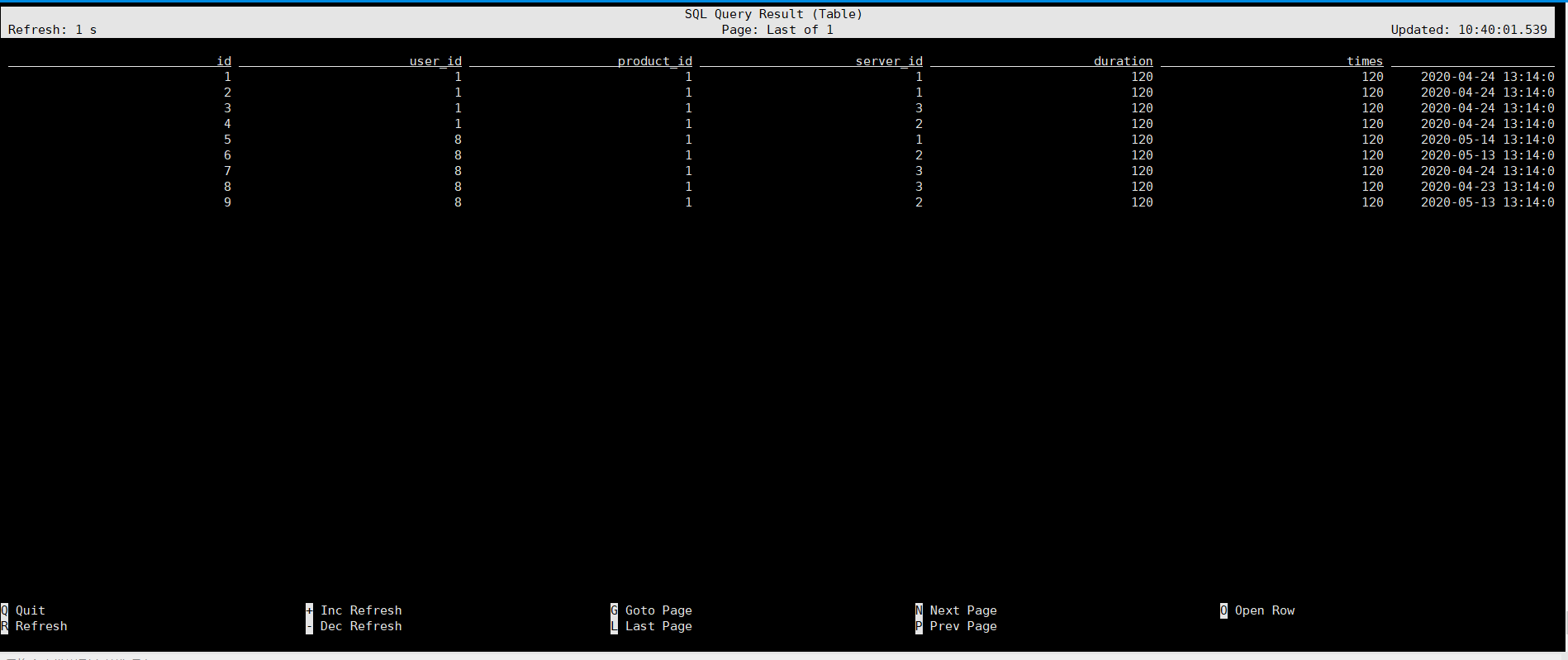
- select * from product_view_sink;

由此可见,sink不能直接使用sql查询。
4)建立同步任务
- insert into product_view_sink select * from product_view_source;
这个时候是可以退出flink sql-client的,然后进入flink web-ui,可以看到mysql表数据已经同步到elasticsearch中了,对mysql进行插入删除更新,elasticsearch都是同步更新的。
查看任务
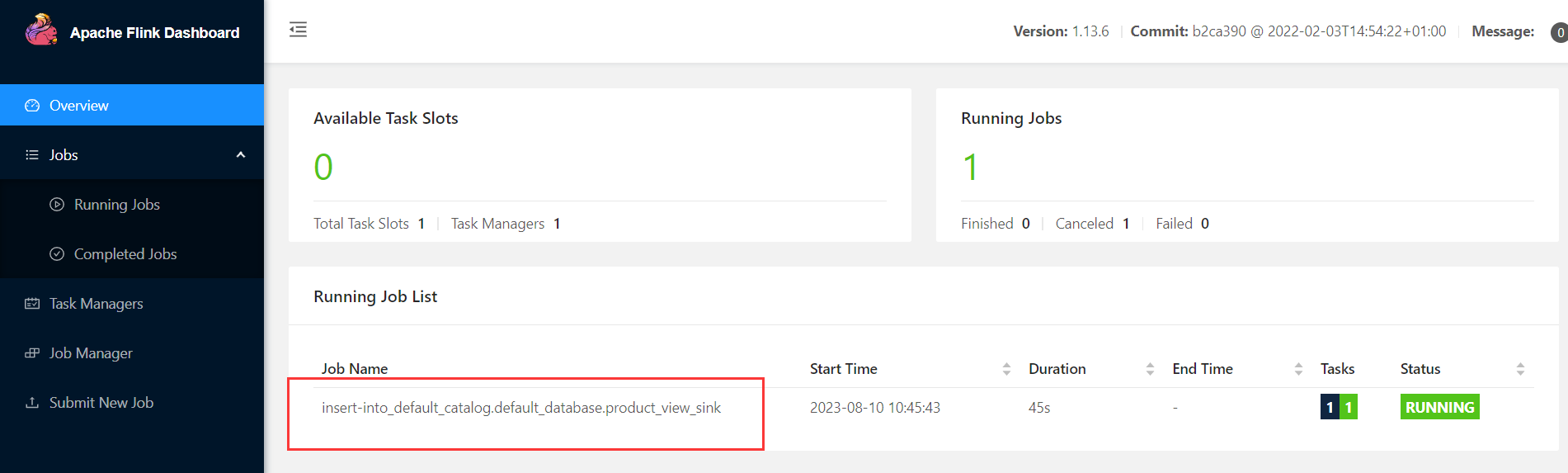
查看es数据
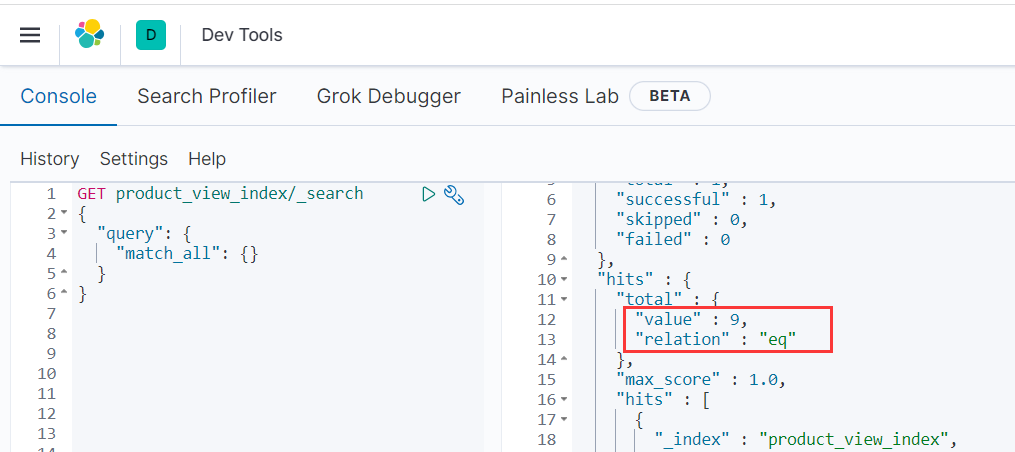
6,数据实时同步
1)新增记录
mysql数据库插入一条记录
- INSERT INTO `product_view` VALUES ('10', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
查询es,新增一条记录
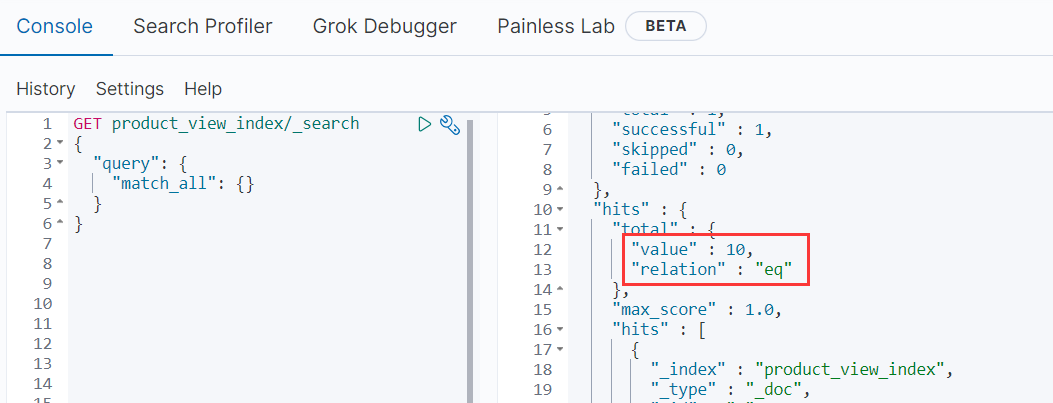
2)删除记录
mysql数据库删除一条记录
- DELETE FROM `product_view` where id=10;
查询es,减少一条记录
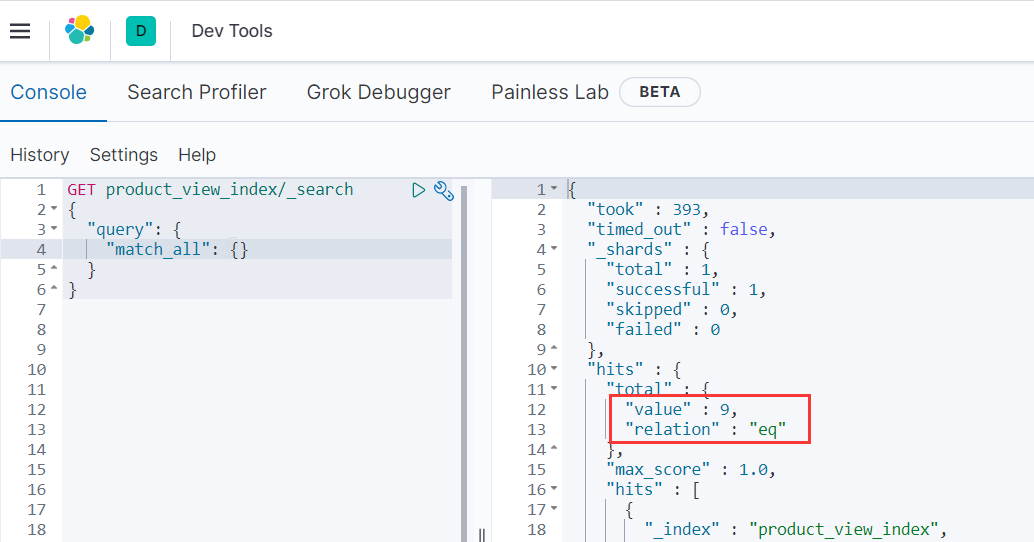
3)更新记录
es原始记录
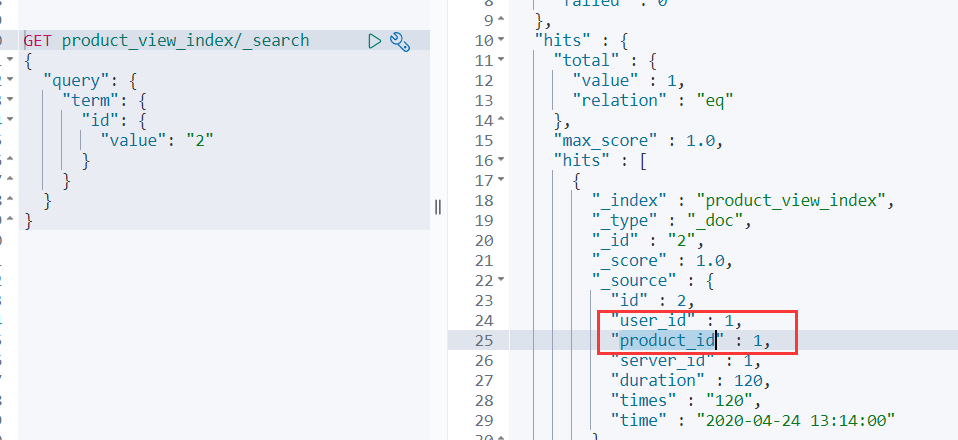
mysql更新一条记录
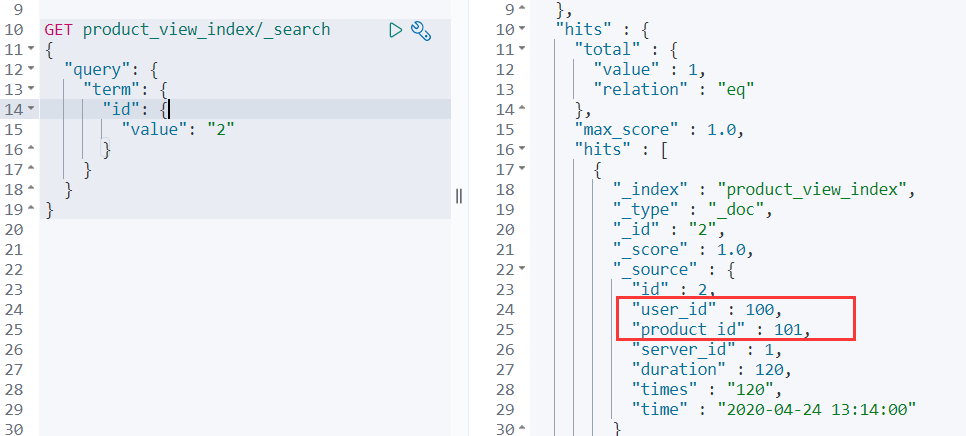
- UPDATE `product_view` SET user_id=100,product_id=101 WHERE id=2;
变更后es记录
7,遇到的问题
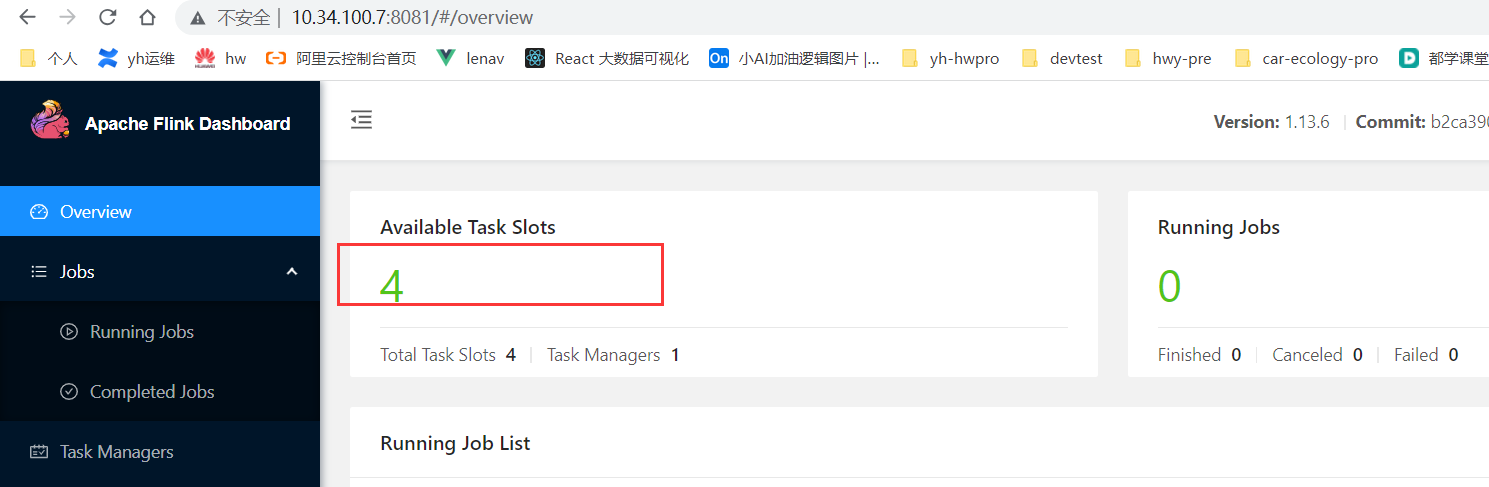
1)资源不足
flink默认taskmanager.numberOfTaskSlots=1即只能运行一个子任务,一般设置为机器的CPU核心数。
2)重复server-id


1、前提:单个提交job任务,即每个insert语句形成一个job,就是一个同步任务。
结论:通过实践可知,所有具有相同server-id的source表,只能选择其中一个且被一个job使用。实用性很差,只是测试时踩的坑记录一下。
场景:假如source1和source2表具有相同的server-id,如果job1中使用了source1(不能同时使用source1和source2),那其他job就不能在用source1、source2了。
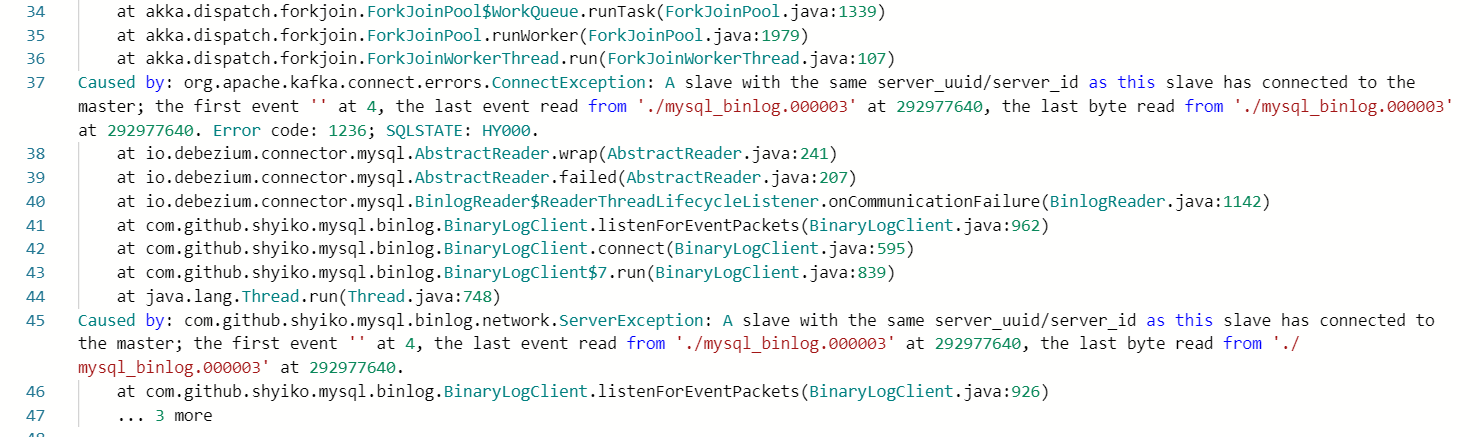
分析:先提交一个job1并且已经在同步了,此时如果提交的job2中有source表与job1中source表有相同的server-id,或job2中使用和job1中重复的source表,那job2也从job1已经读到的binlog位置开始读就会有问题,直接报如下错误。
2、前提:批量提交同步任务,即将多个insert语句放在一起形成一个job,一个insert对应一个同步任务,一个job包含多个同步任务。
结论:通过实践可知,不同的同步任务(即不同的insert语句)可以使用同一个source表,但不建议共享,可能造成数据丢失。但一个同步任务不能使用相同的server-id的source表。
场景:假如source1和source2表具有相同的server-id,如果任务1使用source1(不能同时使用source1和source2),其他任务还可以使用source1。
分析:同时提交任务1和任务2并且都使用到了source1,等于2个任务共同维护source1的binlog状态,此时可能导致某个任务从错误的binlog位置读取数据,从而导致数据丢失。
最佳实践:一个同步任务中(一个insert语句)使用到的每个source表都对应一个不同server-id。同一个source表如在多个job或任务中使用,就在每个job或每个任务中设置不同的表名及server-id。这样对于相同的source表在每个job或任务中都各自维护一份binlog状态了。
举例说明:如order表需要在3个job或同步任务中使用,job1中name=order1,server-id=5401;job2中name=order2,server-id=5402;job3中name=order3,server-id=5403;这样3个job就会各自维护各自的关于order表的binlog状态。