一、深度优先搜索(Depth-First-Search 简称:DFS)
1.1 遍历过程:
(1)从图中某个顶点v出发,访问v。
(2)找出刚才第一个被顶点访问的邻接点。访问该顶点。以这个顶点为新的顶点,重复此步骤,直到访问过的顶点没有未被访问过的顶点为止。
(3)返回到步骤(2)中的被顶点v访问的,且还没被访问的邻接点,找出该点的下一个未被访问的邻接点,访问该顶点。
(4)重复(2) (3) 直到每个点都被访问过,遍历结束。
例无权图:(默认为字母顺序)
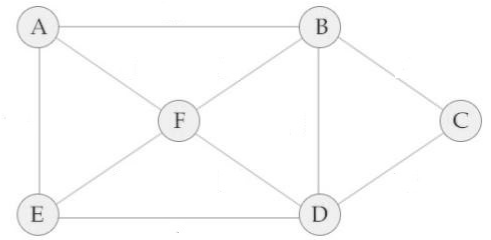
(1)从顶点A出发,访问该图
(2)A的邻接点为BEF 以B为顶点开始访问 B的邻接点有FDC
(3)B的所有的点均被访问结束,访问顶点C 顶点C还有F没有被访问
,结束遍历。
故遍历结果为 A->B->C->D->E->F
有向图:(默认为字母顺序)
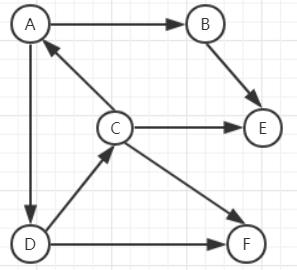
(1)从顶点A出发,访问该图
(2)A 的出路顶点为B、D ,从顶点B 开始访问, B的出路只有E 结束此路;
(3)开始访问顶点D,D的出路为顶点C和F 此时所有顶点都被遍历了,结束;
故遍历结果为: A->B->E->D->C->F
1.2 算法描述
自然语言:从图中的某个顶点v出发,访问v,并将visited[v]的值为true。
一次检查v的所有邻接点w,如果visited[w]的值为flase,再从w出发进行递归遍历,直到图中的所有顶点都被访问过。
伪代码:
递归算法:
visited[MVNum] <-- false
count<--v,visited[v]<--true;
for(w<--FirstAdjVex(G,v);w>=0;w<--NextAdjVex(G,v,w))
if(!visited[w] DFS[G,w]);
采用邻接矩阵表示:
//输入图G(V,E),w表示v的邻接点
//输出邻接矩阵
count<--v; visited[v]<--true;
for(w<--0;w<G.vexnum;w++)
if( (G.arcs[v][w]!=0)&&(!visited[w]) )
DFS(G,w);
采用邻接表:
count<--v; visited[v]<--true;
p<--G.vertices[v].firstarc;
while(p!=NULL) do
w<--p->adjvex;
if(!visited[w]) do DFS(G,w)
p<-- p->nextarc;
1.3用途:检查图的连通性和无环性
1.4总结:每个顶点至多进一次队列。遍历图的过程实质上市通过边找邻接点的过程。因此DFS时间复杂度,当用邻接矩阵表示图时为O(n2),其中n为图中的顶点数,当以邻接表做图的存储结构时,时间复杂度为O(e)这里e为 图中的边数,因此,当以邻接表为存储结构时,DFS时间复杂度为O(n+e)。
二、广度优先搜索(Breadth-First-Search 简称:BFS)
2.1遍历过程如下:
(1)从图中某个顶点v出发,访问v。
(2)依次访问v邻接各个未访问过的的所有顶点
(3)接着从这些邻接顶点中继续访问它们的邻接顶点,遵循原则 先被访问的顶点的邻接点 先于 后被访问的顶点的邻接点 被访问。重复(3)步骤,直至所有的顶点都被访问过。
这里的“先被访问的顶点的邻接点 ”指的是在第二步骤先访问的顶点然后再先访问他的邻接点,包括后来的第三步骤也是这个意思,均为上一步骤 先访问的顶点然后再先访问他的邻接点。
例:图还是上面的那张无权图
我们按照字母ABCDEF这样的顺序来排列
(1)以A为顶点,开始遍历
(2)A的三个邻接点BEF
(3)根据字母顺序 从点B开始访问 B的临界点有CD 此时,所有的顶点均被访问
故,遍历后的结果为 A ->B-> E-> F-> C-> D
若为有向图
(1)根据字母顺序,先从顶点A开始访问
(2)看顶点A的出路,邻接点为B,D 。根据字母顺序,下一个顶点从B开始
(3)顶点B的出路为E ,且E没有出路了,故此路结束
(4)回到和B点同一级的 还有顶点D还没有被访问 D的出路有两条,分别为邻接点C 和F ,此时所有的顶点都被访问过。
故 遍历后的顺序为 A->B->D->E->C->F
2.2算法描述
自然语言:从图 中的某个顶点v出发,访问v,并将visited[v]的值为true,然后将v进队
只要队列不空,则重复下述处理:
队头顶点u出队
依次检查u的所有邻接点w,如果visited[w]的值为false,则访问w,并将visited[w]的数值为true,然后将w入队;
伪代码: //BFS算法描述
//输入:图G=<V,E>
//输出:图G的BFS遍历后的先后次序
visited[v] <--true
InitQueue(Q);
EnQueue(Q,v);
while(!QueueEmpty(Q)) do
DeQueue(Q,u);
for(w <--FirstAdjVex(G,u);w>=0;w<--NextAdjVex(G,u,w))
if(!visited[w]) do
count<<w; visited[w] <--true;
EnQueue(Q,w);
2.3用途:计算最短路径问题
2.4.总结:每个顶点至多进一次队列。遍历图的过程实质上市通过边找邻接点的过程。因此BFS时间复杂度,当用邻接矩阵表示图时为O(n2),其中n为图中的顶点数,当以邻接表做图的存储结构时,时间复杂度为O(e)这里e为 图中的边数,因此,当以邻接表为存储结构时,BFS时间复杂度为O(n+e)。
具体的代码实现如下所示:
- #include<stdio.h>#define N 20#define TRUE 1#define FALSE 0int visited[N]; /*访问标志数组*/typedef struct /*队列的定义*/{int data[N];int front,rear;
- }queue;
-
- typedef struct /*图的邻接矩阵*/{int vexnum,arcnum;char vexs[N];int arcs[N][N];
- }
- graph;void createGraph(graph *g); /*建立一个无向图的邻接矩阵*/void dfs(int i,graph *g); /*从第i个顶点出发深度优先搜索*/void tdfs(graph *g); /*深度优先搜索整个图*/void bfs(int k,graph *g); /*从第k个顶点广度优先搜索*/void tbfs(graph *g); /*广度优先搜索整个图*/void init_visit(); /*初始化访问标识数组*//*建立一个无向图的邻接矩阵*/void createGraph(graph *g)
- {int i,j;char v;
- g->vexnum=0;
- g->arcnum=0;
- i=0;
- printf("\n输入顶点序列(以#结束):\n");while ((v=getchar())!='#')
- {
- g->vexs[i]=v; /*读入顶点信息*/i++;
- }
- g->vexnum=i; /*顶点数目*/for (i=0;i<g->vexnum;i++) /*邻接矩阵初始化*/for (j=0;j<g->vexnum;j++)
- g->arcs[i][j] = 0;/*(1)-邻接矩阵元素初始化为0*/printf("\n输入边的信息(顶点序号,顶点序号),以(-1,-1)结束:\n");
- scanf("%d,%d",&i,&j); /*读入边(i,j)*/while (i!=-1) /*读入i为-1时结束*/{
- g->arcs[i][j] = 1; /*(2)-i,j对应边等于1*/g->arcnum++;
- scanf("%d,%d",&i,&j);
- }
- }/* createGraph *//*(3)---从第i个顶点出发深度优先搜索,补充完整算法*/void dfs(int i,graph *g)
- {int j;
- printf("%c", g->vexs[i]);
- visited[i] = TRUE;for (j = 0; j < g->vexnum; j++)if (g->arcs[i][j] == 1 && !visited[j])
- dfs(j, g);
- }/* dfs *//*深度优先搜索整个图*/void tdfs(graph *g)
- {int i;
- printf("\n从顶点%C开始深度优先搜索序列:",g->vexs[0]);for (i=0;i<g->vexnum;i++)if (visited[i] != TRUE) /*(4)---对尚未访问过的顶点进行深度优先搜索*/dfs(i,g);
- printf("\n");
- }/*tdfs*//*从第k个顶点广度优先搜索*/void bfs(int k,graph *g)
- {int i,j;
- queue qlist,*q;
- q=&qlist;
- q->rear=0;
- q->front=0;
- printf("%c",g->vexs[k]);
- visited[k]=TRUE;
- q->data[q->rear]=k;
- q->rear=(q->rear+1)%N;while (q->rear!=q->front) /*当队列不为空,进行搜索*/{
- i=q->data[q->front];
- q->front=(q->front+1)%N;for (j=0;j<g->vexnum;j++)if ((g->arcs[i][j]==1)&&(!visited[j]))
- {
- printf("%c",g->vexs[j]);
- visited[j]=TRUE;
- q->data[q->rear] = j; /*(5)---刚访问过的结点入队*/q->rear = (q->rear + 1) % N; /*(6)---修改队尾指针*/}
- }
- }/*bfs*//*广度优先搜索整个图*/void tbfs(graph *g)
- {int i;
- printf("\n从顶点%C开始广度优先搜索序列:",g->vexs[0]);for (i=0;i<g->vexnum;i++)if (visited[i]!=TRUE)
- bfs(i,g); /*从顶点i开始广度优先搜索*/printf("\n");
- }/*tbfs*/void init_visit() /*初始化访问标识数组*/{int i;for (i=0;i<N;i++)
- visited[i]=FALSE;
- }int main()
- {
- graph ga;int i,j;
- printf("***********图邻接矩阵存储和图的遍历***********\n");
- printf("\n1-输入图的基本信息:\n");
- createGraph(&ga);
- printf("\n2-无向图的邻接矩阵:\n");for (i=0;i<ga.vexnum;i++)
- {for (j=0;j<ga.vexnum;j++)
- printf("%3d",ga.arcs[i][j]);
- printf("\n");
- }
- printf("\n3-图的遍历:\n");
- init_visit(); /*初始化访问数组*/tdfs(&ga); /*深度优先搜索图*/init_visit();
- tbfs(&ga); /*广度优先搜索图*/return 0;
- }
运行结果(输入的为本节中一直用到的无向图)
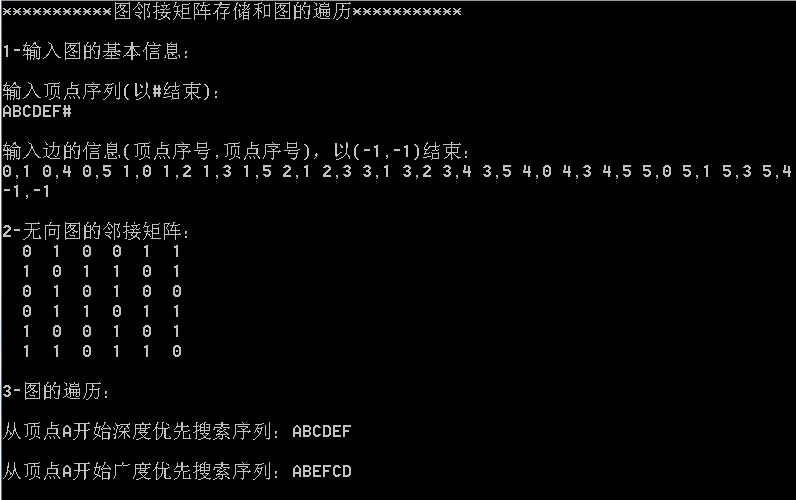
深度和广度查找不同之处在于对顶点的访问顺序不同。
第一次写博客,应该还是有点问题的(虽然也查了一些资料~.~)

ball ball you can point my errors! thanks a lot !
参考资料:
《数据结构(C语言版)》 严蔚敏 李冬梅 吴伟民著 人民邮电出版社
《程序设计中实用的数据结构 》 王建德 吴永辉著 人民邮电出版社
