进程间通信
1.什么是通信
- 数据传输:一个进程需要将自己的数据传输给另一个进程
- 资源共享:多个进程同时共享一个资源
- 进程事件:一个进程向一组(或一个)进程通知某一事件,如:子进程结束要通知父进程来回收资源
- 进程控制:有些进程需要知道另一个进程的状态,控制拦截另一个进程陷入异常等,如:gdb调试
2.为什么要有通信
多个进程之间需要协同来完成某项任务:
eg:
cat log.txt | gerp "hehe"
具备通信的的前提条件:
3.进程间通信分类
? 管道通信
? System V IPC
- System V 消息队列
- System V 共享内存
- System V 信号量
? POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
4.管道
对于文件系统来说,被打开的文件在文件描述符表里有对应的fd (文件描述符)
当一个进程fork()后,子进程会拷贝父进程的大部分资源,其中就包括文件struct files_struct,当然,**file* fd_array **也拷贝过去,即文件描述符表
所以子进程能指向和父进程同一个被打开的文件所以子进程创建后,打开的文件和父进程指向的是同一个文件
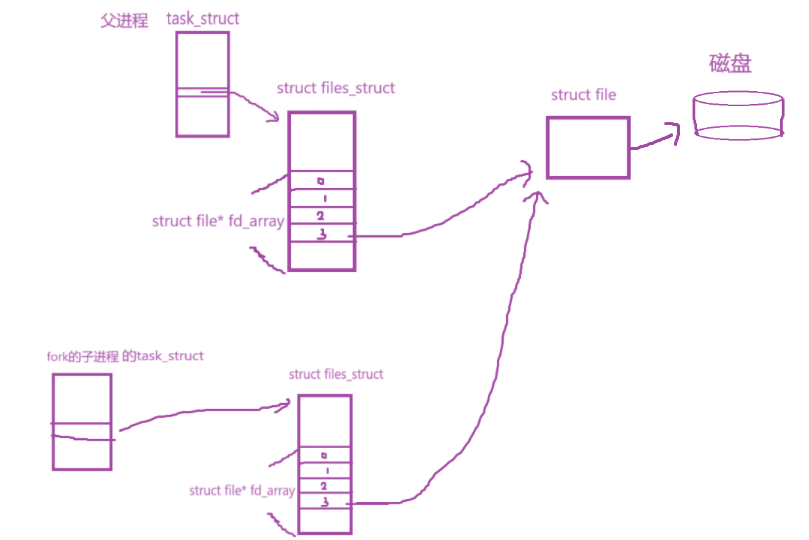
此时就初步具备了通信的条件,这个空间是由文件系统提供的,文件在磁盘里
但是,文件系统需要访问外设(即磁盘),所以访问速度相对较慢
4.1管道文件的定义和实现
有一种内存级的文件,他没有对应的磁盘文件,但是有自己的file结构体,这个实现是操作系统本身用联合体实现的,这个细节实现是OS去操作的。
对于每个struct file都有
1.file的操作办法 2. 内核缓冲区
-
对于一个struct file,可以不指向磁盘中的文件,因为这个实现是操作系统来实现的
-
所以操作系统在内存中创建一个不指向磁盘中任何文件的struct file,即只有一个结构体,这个结构体里当然也具备了1.file的操作办法 2. 内核级缓冲区,所以进程之间可以通过这个匿名文件的缓冲区来进行通信
-
当父进程打开一个内存级文件的时候,fork子进程,子进程也具备了指向该内存级文件,所以父子进程可以用这个内存级文件来进行通信,不需要访问磁盘就可以完成,所以速度就会大大提升,这个文件没有名字,所以叫做匿名管道
-
如下图
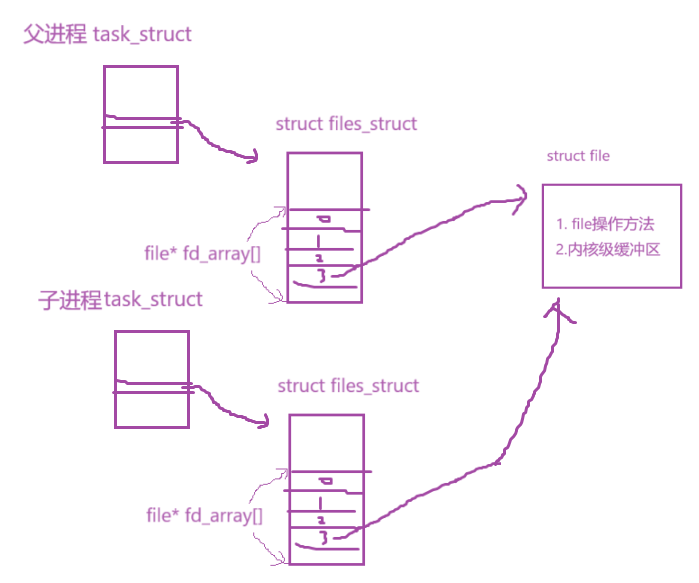
这种父子进程之间,用内核级文件进行通信的文件称为:管道文件
4.2 管道的创建过程
管道在生活中就是用来单向传输的,一头输入一头只输出
管道需要读和写,所以一个父进程需要同时具备读和写权限的属性才能fork子进程,要不然子进程没办法进行读或者写
但是又不能父子进程两个都写,或者都读,只能一方写,一方读
所以创建过程如下:
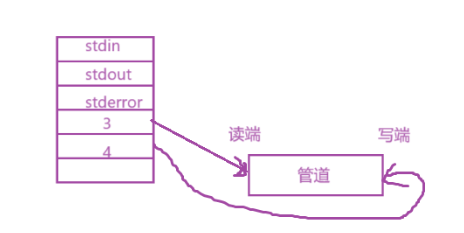
- 2.父进程fork()子进程,这样一来,子进程也都具备了对该内存级文件读和写的方式

- 关掉一个读的和一个写的
fd,如果没关,万一没关可能会被不小心访问到
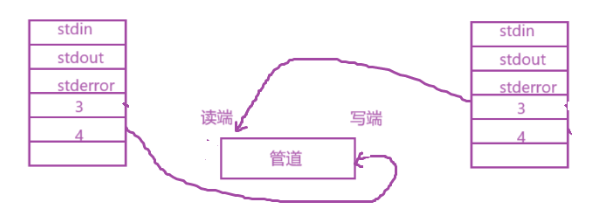
?管道是一个父进程分别以读和写方式打开一个内存级文件,并通过fork创建一个子进程,各自再关闭对应的读写端,进而形成一条通信信道,这样的信道是基于文件的,所以叫做:管道
匿名管道 :目前只能用来进行父子进程间通信
4.3 pipe创建管道
#include <unistd.h>//功能:创建一无名管道//原型int pipe(int fd[2]);//输出型参数fd:文件描述符数组,其中fd[0]表示读端, fd[1]表示写端返回值:成功返回0,失败返回错误代码
联想记忆法 : 1. fd[0]:0比作嘴巴,读东西,读端
2. fd[1]: 1比作笔,写东西,写端
在fork子进程后,父子进程是读还是写,那么就关闭不用的一个,fork()之后各自关掉不用的描述符
4.4 匿名管道的读写特征
-
读慢,写快
写的速度>读的速度,管道也是有最大容量的
所以当管道被写满时,将不在继续写,直至读端读走数据有可以写的空间,写端才继续写
-
读快,写慢
读的速度>写的速度
因为读速度大于写速度,所以当读端读完管道内的内容时,此时已经没有内容可读了,那么进程将阻塞在read函数这里,等待写端写,直至管道内有数据可继续读
-
写端关闭,读端不关闭
当管道写端关闭时,读端读完管道内的数据时,如果再次去读没有数据的管道会返回0,相当于读到了EOF
-
读端关闭,写端不关闭
读关闭,操作系统将给进程法信号,终止写端,因为不需要读的话,就是浪费系统资源,操作系统会强制终止写端
4.5 命名管道
1.mkfifo函数创建命名管道
#include<sys/types.h>#include<sys/stat.h>int mkfifo(const char *pathname,mkde_t mode);
? pathname : 要创建命名管道的目录和文件名
-
返回值
成功返回 0 ,失败返回 -1
-
命名管道的文件类型是p
2.命名管道的原理
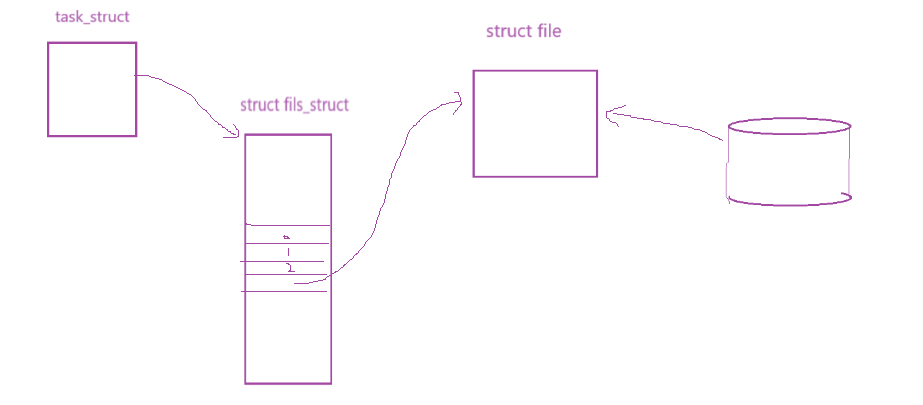
在进程中打开命名管道文件的方法跟普通文件一样
- 文件从磁盘中加载到内存,然后创建
struct file,然后将其地址放到task_struct中的files_struct中的文件描述符表中
- 但是不一样的是,我们只与struct file中的内核缓冲区交互,读写的内容都保存在struct file中的缓冲区中,自始至终没有将内容写到磁盘,磁盘文件相当于一个载体,只是为了给我们提供一个
struct file
- 如下图流程
3.两个无血缘进程间的通信
让两个进程看到同一份命名管道,然后分别选择一个读和写
注意细节:当只有一端打开命名管道时,eg:只打开读端,另一端还没就绪,此时打开的一端会阻塞自己,等待另一端就绪
5.共享内存
共享内存区是最快的IPC形式,一旦这个shm与进程地址空间映射,那么无需通过内核进行通信,直接通过一个内存进行通信,但是由于共享内存只能在本地进行多个进程间通信,所以就慢慢的被淘汰掉了了
5.2 共享内存的原理
- 首先要拿到一个
key,生成一个独一无二的key,其他进程(人)进来需要key,创建共享内存时候要传这个key就好比开个房间
- 然后让进程的进程地址空间与这个共享内存区域建立映射关系,这样进程就拿到了读写共享内存的功能
- 此时进程之间就具备了通信的基本能力:看到同一份公共资源,就可以进程进程之间通信了
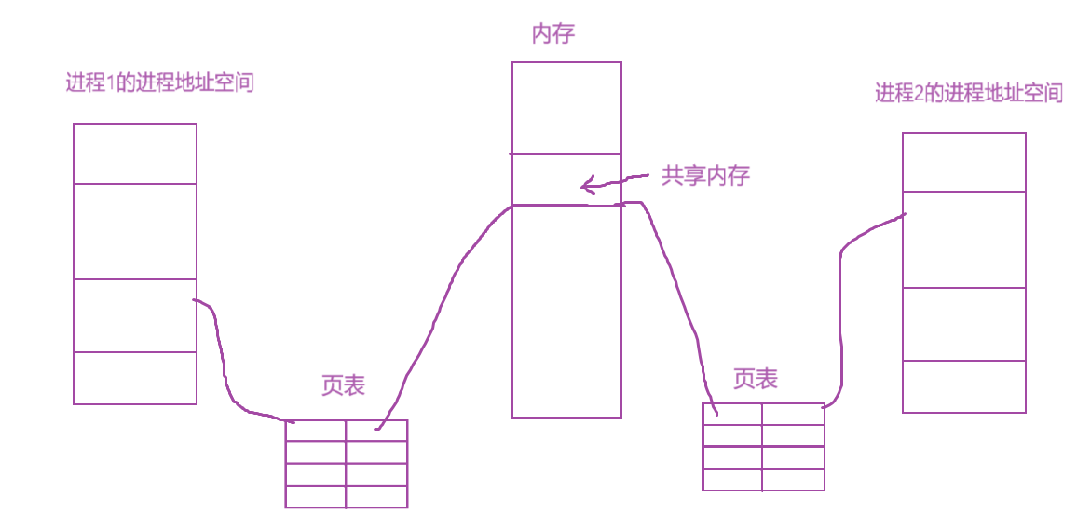
如上图,通过页表映射到各自的进程地址空间,从而实现两个进程可以实现进程间通信
5.3 共享内存的实现
#include <sys/types.h>#include <sys/ipc.h>key_t ftok(const char *pathname, int proj_id);//pathname放一个指定的路径即可,proj_id指定一个数值即可,但是记得另一个进程对应得这两个参数也要一样
#include <sys/ipc.h>#include <sys/shm.h>int shmget(key_t key, size_t size, int shmflg);//key即上边得Key , size为开辟共享内存得大小单位是字节
? 参数:shmflg 是一个用标志位代表的一个参数有两个IPC_CREAT,IPC_EXCL
IPC_CREAT : 如果没有那么创建共享内存,如果已经有了,那么返回共享内存的shmid
IPC_EXCL : 该宏必须和IPC_CREAT一起使用,否则没有意义。当shmget取IPC_CREAT|IPC_EXCL时,表示如果发现信号集已经存在,则返回-1,错误码为EEXIST。
创建时必须加上创建共享内存的权限码0600
//1.创建时一般用下边这个int shmid=shmget(key,4096,IPC_EXCL|IPC_CREAT|0600);//2.获取时用下边的这个int _shmid=shmget(key,4096,IPC_CREAT);
? 返回值 :成功返回共享内存的shmid,失败返回-1
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数: hm_addr指定共享内存连接到当前进程中的地址位置,通常为空(nullptr),表示让系统来选择共享内存的地址。
? shm_flg是一组标志位,通常为0
- **④断开与共享内存链接 shmdt()函数 **
int shmdt(const void *shmaddr);
参数shmaddr是shmat()函数返回的地址指针,调用成功时返回0,失败时返回-1.
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
- IPC_STAT:把shmid_ds结构中的数据设置为共享内存的当前关联值,即用共享内存的当前关联值覆盖shmid_ds的值。
- IPC_SET:如果进程有足够的权限,就把共享内存的当前关联值设置为shmid_ds结构中给出的值
- IPC_RMID:删除共享内存段
- 返回值 : 失败返回 -1
6.信号量
- 信号量:信号量本质是一个计数器,用来表示公共资源中可用的数量
- 公共资源 :可用被多个进程同时访问的资源,叫做公共资源
为什么要让不同的进程看到同一份公共资源呢---->为了不同进程之间进行通信,协同工作等------>那么就让不同的进程看到同一份资源------->提出产生公共资源的方法----->过程中遇到问题------>数据不一致问题,比如还没有写完另一边就开始读取了
-
临界资源 : 被保护起来的公共资源被称作临界资源(临界资源占少数,因为大部分资源都是各自进程自身的,只有进程要通信并且防止被打扰才会进行保护,所以临界资源在这个条件下占少数)
-
临界资源(内存,文件,网络等)是要被使用的,如何被进程使用呢?进程存在对这部分资源的使用方法代码,由这部分代码来实现,那么这部分代码区域被称作临界区 ,其他区域则被称作非临界区
-
如何保护:互斥和同步
-
原子操作 : 对于一件事情 , 要么就一开始就不做,要么做了就做完
-
对于共享资源的使用:1.作为一个整体 2.拆分成若干个部分使用
所有的进程在访问公共资源的前提下,需要先申请信号量------>所以必须进程都能看到信号量,那么信号量也是一个公共资源----->所以信号量也要保证自己的安全------->所以信号量进行++或者- -操作是原子性的
? 那么, 对于信号量获取资源进行信号量--的操作被称为P操作
? 对于信号量回收资源进行信号量++的操作被称为V操作
7. IPC资源的组织方式
? 系统的IPC资源常见的有:消息队列,共享内存,信号量等
? 这些资源都包括了两个结构体:1.自身的结构体例如struct shm_ds或者sem_ds 2.struct ipc_prem
这些资源是由OS统一管理的,OS会创建一个数组 : ipc_prem *prems[ ];,由这个数组统一管理ipc资源
- 在创建对应得ipc资源时,会先创建一个自身类型得结构体,比如shm就会创建
shm_ds
- 对于一个结构体,结构体的起始地址==结构体第一个元素的地址,所以对于每个ipc资源的自身结构体,有以下内容,其中第一个元素为创建了一个ipc_prem对象,然后将其地址放到OS的prems数组中,以方便统一管理,这样,OS就会知道管理诸多ipc资源中,所要处理的当前ipc资源类型是什么了
- 例如 : prems[0]=&semid_ds.sem_prem;

